
1 引言
视觉搜索过程往往伴随着大量的信息输入,人们只选择与当前任务相关的目标信息进行加工,此时其他的信息就作为注意背景而存在。尽管背景信息大多是无效的,但其中一些规律性信息仍可以引导眼球运动,使目标相关信息维持在视野中央(Chun & Nakayama, 2000)。当场景中的规律性信息重复出现时,可以引导更快的行为反应,这种现象被称为背景线索效应(Chun & Jiang, 1998)。其潜在机制是对目标与场景之间联结关系的内隐学习(Chun & Jiang, 1998; Xie et al., 2020)。背景线索效应分为感知觉加工、注意引导和反应选择三个阶段(Wolfe et al., 2011)。眼动研究发现背景线索效应是注意引导和反应选择二者协同作用的结果(Harris & Remington, 2017; Peterson & Kramer, 2001)。Schankin和Schubö(2010)将背景线索效应与脑电技术结合,进一步为注意引导(N2pc)和反应选择(LRP)在任务加工中起到重要作用提供了神经基础。
本研究拟采用隐马尔可夫模型(hidden Markov model, HMM)探究背景线索效应加工的动态过程及个体差异。在传统的背景线索效应研究中,个体差异的探讨往往仅限于描述性分析。例如,Yang等(2021)通过学习阶段与转换阶段的相关性,将被试分为“早习得组”和“晚习得组”。其他研究则是基于特定的群体特征进行分组(李士一 等, 2022; Edwards & Shin, 2017; Kojouharova et al., 2023)。然而现有研究尚未深入探讨个体差异背后的认知过程。在认知任务中不同的策略会导致不同的眼动模式,这些策略通常是隐藏的,需要从数据中推断出来(Kucharský et al., 2020)。HMM以一种数据驱动的方法来识别被试间不同的眼动模式,为揭示行为与认知之间的联系提供了新证据。有关面孔识别的研究采用HMM并聚类,发现不同文化背景下个体的眼动模式存在差异(Chuk et al., 2014; Chuk et al., 2017)。Chan等(2020)将情绪面孔与HMM方法相结合,发现高社交焦虑的个体对于中性和愤怒面孔采用同样的眼动模式,而低社交焦虑个体会转换眼动模式。
传统眼动研究中的兴趣区划分存在三个主要问题:首先,这种方法通常是人为提前画出兴趣区,缺乏客观性。其次,将超出兴趣区的大量数据视为无效数据摒弃,而这些数据本身包含认知加工的动态信息,摒弃这些数据将无法反映视觉搜索的整体模式(Wang et al., 2019)。最后,不同研究划分的兴趣区没有统一的标准,可能导致不同研究间的结果不一致,影响研究的外部效度。Cho等(2022)采用面孔识别材料对比预先画好的兴趣区与HMM聚类的兴趣区,结果发现人为划定的兴趣区只涉及口部区域,而HMM则聚类出口部区域以及口鼻部区域两个兴趣区。此外人为划定的兴趣区大小是固定的,而HMM聚类出的兴趣区根据个体差异大小存在差异。
首次注视点的百分比和注视次数常作为探究注意在空间维度转移的指标(Pereira & Castelhano, 2019; Peterson & Kramer, 2001; Zhao et al., 2012)。此外,眼动时间序列分析常用来探究注意的时程变化。Seitz等(2023)通过可视化扫描路径发现,在重复场景条件下,扫视行为呈现出更系统化的顺序执行。这是由于重复场景中的眼动扫描路径得到了优化(Seitz et al., 2024),从而更有效地定位到目标位置。然而,传统的分析方法往往忽略了个体差异对背景线索效应的影响,将其视为噪声通过叠加平均的方式予以抵消,掩盖了不同被试在搜索路径上的差异。本研究采用HMM中的隐藏状态概率转换矩阵,为每个被试在不同兴趣区之间随时间的转换提供了数据支持,从而揭示了个体差异在背景线索效应中的作用(Chan et al., 2020; Chuk et al., 2014; Chuk et al., 2017; Hsiao et al., 2021)。
综上,相比于传统的眼动分析方法,HMM以数据驱动的方式, 通过隐藏状态及其转换概率来代表眼动的不同模式,揭示潜在的认知加工过程。其优势在于:(1)捕捉个体差异,探索不同被试在视觉搜索过程中认知过程的差异性;(2)以数据驱动的方式更加客观合理地划分兴趣区;(3)能有效地分析眼动数据的时间序列信息,更好地理解注意在时间维度上的动态变化。因此,本研究将使用眼动技术考察在注意引导过程中背景线索效应的加工机制及眼动模式的个体差异。采用HMM分类器以数据驱动的方式划分兴趣区,以被试为单位分别对重复场景和新异场景的眼动模式进行聚类,考察背景线索效应在视觉搜索模式上的个体差异。同时,考虑到反应选择阶段的眼动加工主要体现在最后一次眼动距离按键响应之间的时间,这可能会影响眼动模式的聚类,本研究将在学习阶段采用固定的搜索时间,在整体眼动数据的空间和时间维度上对个体差异的眼动模式进行定量分析。
2 研究方法
2.1 被试
本研究随机招募37名大学生被试(男性12名,女性25名,平均年龄为21.00±3.78岁),所有被试均为右利手,视力或矫正视力正常。剔除探针正确率低于80%的3名被试,剔除眼动数据记录有问题的3名被试,有效被试共31名。本实验通过天津师范大学科学研究伦理委员会审批且所有被试知情同意,并在实验结束后给予相应的报酬。
2.2 实验材料
本实验使用E-Prime 3.0设计并呈现在19英寸的显示器上,分辨率为1024×768像素,刷新率为60 Hz。搜索界面包含1个目标刺激“T”和11个分心刺激“L”。“T”和“L”都是由两条等长的黑色线段组成,如图1 所示。其中,目标刺激为顺时针旋转90°或270°的字母“T”,干扰刺激为顺时针旋转0°、90°、180°、270°的字母“L”。目标刺激和干扰刺激随机呈现在8×6的虚拟网格中(视角大小为24°×18°)。为了排除刺激共线对实验的影响,将每个刺激的位置在水平和垂直方向进行了[−0.2°, 0.2°]范围的随机抖动。此外刺激界面随机出现大小为1°×1°的探针方块。实验分为重复场景和新异场景两个条件,重复场景是指目标刺激与分心刺激的场景位置保持不变,新异场景是指目标刺激与分心刺激的场景位置随机变化。为了排除位置概率效应,整个实验中目标位置均匀分布在四个象限中的16个位置,其中8个为重复场景的目标刺激的位置,8个为新异场景的目标刺激的位置。

2.3 实验流程
正式实验前有30个练习试次,练习场景与正式实验的场景不同。整个实验包括学习和测试两个阶段。学习阶段在每次实验开始时,首先在屏幕的中央呈现一个黑色注视点“+”800~1100 ms,注视点消失后出现搜索界面,由旋转的目标“T”和分心物“L”组成,要求被试找到目标“T”并进行注视,持续2000 ms。搜索界面呈现后随机出现黑色或白色探针刺激,要求被试对黑色探针不做反应,白色探针按空格键以检测被试是否走神。试次间隔为500 ms。测试阶段没有探针刺激,搜索界面为16张场景图片,8张重复场景,8张新异场景,要求被试找到旋转的目标“T”,顺时针旋转90°按“f”键,270°按“j”键。学习阶段和测试阶段都包含8个实验组块,每个组块内有16个试次,一半为重复场景一半为新异场景并在被试间平衡。
本实验使用台式EyeLink 1000 Plus眼动仪记录被试的眼动指标,采样率为1000 Hz。被试坐在电脑屏幕前,头枕在下巴垫上,视线与屏幕中心保持水平,视距为60 cm。学习阶段开始前采用9点校准,且每当漂移校准误差大于1°时需要重新校准。
2.4 隐马尔可夫模型
一阶马尔可夫模型是一个时间序列模型,是指下一时刻的状态只由其前一时刻的状态决定。然而,状态有时并不是直接可见的(隐藏状态“I”),但受隐藏状态影响的某些变量则是可见的(观测状态“O”),隐藏状态可以通过观测状态与隐藏状态之间的概率关联以及隐藏状态与隐藏状态之间的转换概率进行估计(αij),如图2a 所示,这就是隐马尔可夫模型(HMM)。HMM包含三个成分:初始状态、初始概率和状态转换概率。本研究的初始状态对应于刺激界面的兴趣区(region of interest, ROI),观测状态对应于刺激界面的注视点,每个ROI注视点的分布都遵循在二维笛卡尔坐标系中高斯分布X~N(μ, σ)。初始概率是指被试在首次注视点落在每个ROI的概率(π)。状态转换概率是指注视点从一个ROI转移到其本身或下一个ROI之间的转换概率矩阵,如图2b 所示。
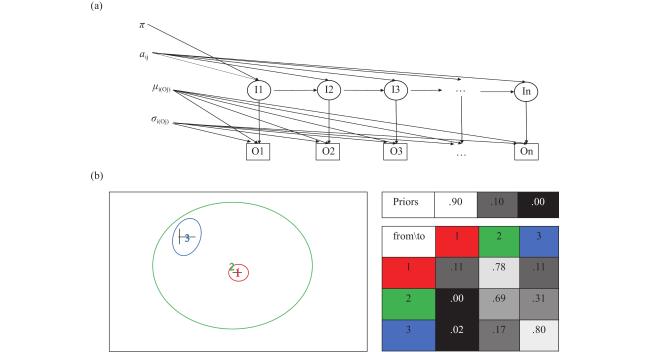
变分贝叶斯期望最大化(variational Bayesian expectation maximization, VBEM)是用来估计HMM最佳参数的方法。首先将HMM的参数使用MATLAB中的fit函数变为高斯分布。在E步中使用前向后向算法(forward-backword)计算单一和成对的期望值,分别对应于特定时间的单一状态的边际概率和两个连续状态的联合概率。在M步中更新模型参数使得E步所求的期望值最大化。重复E步和M步直到收敛。
2.5 数据分析逻辑
为了探究重复场景和新异场景的眼动模式是否存在差异,将两种场景的眼动数据分别训练1到6个ROI,通过概率转换矩阵发现3个ROI即可包含目标搜索的全部路径,因此后续分析均使用3个ROI进行训练(Chuk et al., 2017)。由于每个场景中目标的位置各不相同,无法对不同目标位置的所有场景进行同质化比较,进一步将每个目标位置的重复场景和新异场景分别训练HMM。但由于场景在被试间平衡,同一个目标位置对于某一个被试来说只可能是重复场景或新异场景,因此本研究在16个场景中分别在两种条件下对两组被试进行独立样本t检验。对于每个目标位置而言,由于两组被试数不均等(14 vs 17),本研究通过Bootstrap方法克服样本量不均等的问题,将被试数多的一组进行随机后取前14行数据与另一组数据计算对数似然数矩阵(log-likelihood, LL),并对两组LL进行独立样本t检验,这一过程重复1000次。
每个重复场景和新异场景下根据所有被试HMM的相似性将其聚类生成两个具有代表性的HMM,以描述组内共同的眼动模式。根据不同的HMM,计算出两组被试的最可能搜索路径。为了确保习得拟合更好的模型以及避免收敛到局部最大值,参考前人的研究方法,本研究进行100次迭代,每次迭代HMM参数都进行随机的高斯分布(Cho et al., 2022; Chuk et al., 2014)。最终选择最大对数似然比的模型参数。工具箱“隐马尔可夫模型眼动分析”可从以下网址下载:http://visal.cs. cityu.edu.hk/research/emhmm/。
3 结果
3.1 非线性混合模型与传统方差分析
在数据分析之前,剔除小于200 ms或大于3个标准差的试次,其中学习阶段与测试阶段分别剔除5.8%和1%的数据。相比于传统的重复测量方差分析方法,非线性混合效应模型(nonlinear mixed-effects modeling, NLME)将时间段从分类变量改为了连续变量,更符合背景线索效应的学习曲线(Brooks et al., 2010; Young et al., 2009)。采用Y=y0tk的双参数幂函数进行拟合,其中Y为因变量,y0为截距参数,t为时间段,k为非线性函数的斜率参数(Brooks et al., 2010; Chun & Jiang, 2003)。学习阶段的拟合曲线如图3a 所示,截距参数拟合显著大于0,t(1, 462)=43.85,p<0.001,重复场景的截距显著低于新异场景,t(1, 462)=−2.54,p=0.012,说明重复场景的习得比新异场景更容易。斜率参数在两种场景条件下没有显著差异,说明重复场景与新异场景的学习曲线相似。
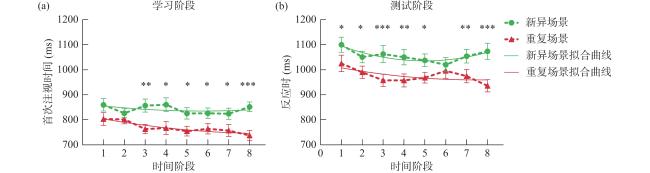
对学习阶段的首次注视时间进行2(场景条件:重复场景、新异场景)×8(时间阶段:1、2、3、4、5、6、7、8)的重复测量方差分析,场景主效应显著,F(1, 30)=31.80,p<0.001,η${_{\rm p}^2} $ =0.52,重复场景的首次注视时间显著快于新异场景,时间阶段主效应及二者的交互作用不显著。对重复场景和新异场景的8个组块进行配对样本t检验以考察背景线索效应的学习过程,结果发现重复场景条件下第3~8个组块的首次注视时间显著快于新异场景条件(ps<0.05),说明被试在第3个组块开始习得背景线索效应。
对测试阶段的反应时进行同样的分析,如图3b 所示,重复场景的截距显著低于新异场景,t(1, 462)=−3.32,p=0.001,重复场景与新异场景的斜率没有显著差异。重复测量方差分析发现场景主效应显著,F(1, 30)=38.93,p<0.001,η${_{\rm p}^2} $ =0.57,重复场景显著快于新异场景,时间阶段主效应不显著,二者的交互作用边缘显著,F(7, 210)=1.84,p=0.081,η${_{\rm p}^2} $ =0.06。简单效应分析发现重复场景的反应时在每个时间段都显著快于新异场景(ps<0.05),除了第6个组块。说明被试在学习阶段习得的背景线索效应在测试阶段依然存在。
3.2 HMM计算场景以及个体差异
所有被试具有代表性的HMM如图4a 所示,被试普遍的搜索模式为从中央注视点到全局搜索。然而HMM训练出的ROI过于广泛,这是由于目标均匀分布在搜索界面导致的。因此在所有目标位置下训练所有被试的眼动数据得到每个目标位置下每个被试的HMM,ROI的区域更小且包含目标位置,如图4b 所示。相比于新异场景,重复场景下ROI区域更小说明注视点分布更集中。分别在每个目标位置条件下的重复场景和新异场景进行比较,相比于新异场景,重复场景出现全局搜索的概率更高(priors ROI2)且转移到目标位置的概率更高(from ROI2 to ROI3),如图4c 。接下来分别对16个目标位置两种场景下的对数似然数向量矩阵进行差异检验,由于两组被试人数不均,采用1000次Bootstrap的方法抽样,而后进行单尾独立样本t检验并做FDR矫正,结果表明重复场景组被试在重复场景的对数似然数显著高于新异场景组,ts>5.31,ps<0.05。类似的,新异场景组被试在新异场景的对数似然数显著高于重复场景组,ts>4.92,ps<0.05。这说明无论目标在什么位置,重复场景和新异场景的HMM的眼动模式均存在显著的不同。
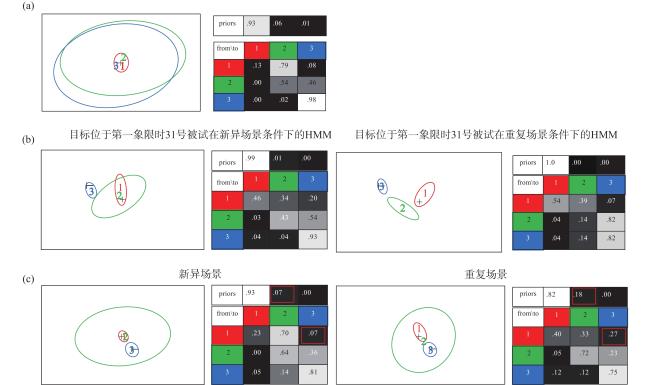
使用VBEM对所有重复场景下所有被试的HMM进行聚类,发现被试存在两类最可能搜索路径:第一组被试最可能的搜索路径为:注视点到全局搜索到目标(1-2-3),该路径概率为0.52,是一种定向搜索模式。第二组被试最可能的搜索路径为:注视点到全局搜索到全局搜索(1-2-2),该路径概率为0.39,是一种全局搜索模式。为了研究定向搜索模式与全局搜索模式的HMM是否显著不同,在定向搜索模式下被试的注视点序列中分别计算全局搜索模式和定向搜索模式的对数似然数。类似的,在全局搜索模式下被试的注视点序列做同样的分析。对两种眼动模式得出的对数似然数进行配对样本t检验,结果发现全局搜索[t(20)=7.55, p<0.001, Cohen’s d=1.65]与定向搜索[t(9)=4.57, p=0.001, Cohen’s d=1.44]的眼动模式存在显著差异。同样的,对新异场景也做相同的分析,t(20)=8.84,p<0.001,Cohen’s d=1.93;t(9)=4.07,p=0.001,Cohen’s d=1.29。结果表明两组被试的眼动模式存在显著差异,无论在重复场景还是新异场景,同一组被试均具有类似的眼动模式。
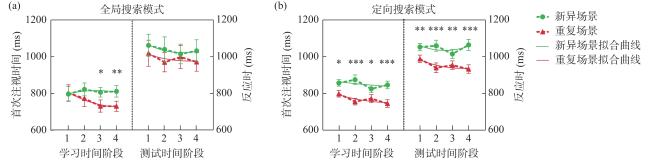
根据不同被试的眼动模式,将被试分为两组:全局搜索组与定向搜索组,其中被试3和被试19由于跨情景的搜索模式不同而被排除。为进一步增强统计检验力,将8个组块按时间顺序分为4个时间阶段。分别为全局搜索组和定向搜索组构建非线性混合效应模型,结果如图5 所示,全局搜索模式组在学习阶段中重复场景和新异场景的斜率参数与场景出现边缘显著,t(1, 59)=−1.94,p=0.057,重复场景的学习好于新异场景。分别将每一个时间段的不同场景的首次注视时间进行配对样本t检验,结果发现在第三(p=0.026)和第四(p=0.003)时间段,重复场景显著快于新异场景,说明被试逐渐习得了背景线索效应。该组被试在测试阶段中的差异不显著,说明采用全局搜索模式的被试在注意引导阶段习得的背景线索效应不能影响测试阶段的整个背景线索效应的产生。定向搜索模式组在学习阶段截距参数与场景条件的交互作用显著,t(1, 137)=−3.23,p=0.002,重复场景的截距显著低于新异场景,说明重复场景的习得更容易。分别将每个时间段的不同场景进行配对样本t检验,结果发现所有时间段重复场景的首次注视时间均快于新异场景(ps<0.05),说明被试习得了背景线索效应。测试阶段出现了类似的结果,截距在不同场景条件下出现显著差异,t(1, 137)=−2.99,p=0.003。分别将每个时间段的不同场景进行配对样本t检验,结果发现在所有时间段均出现了背景线索效应(ps<0.01)。上述结果说明被试差异是导致背景线索效应出现分离的一个关键因素。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 讨论
本研究采用隐马尔可夫模型(HMM)利用眼动的时间和空间信息,分析重复场景和新异场景在经典背景线索效应中眼动模式的差异。研究发现重复场景对目标的首次注视时间显著快于新异场景,与前人研究一致(Harris & Remington, 2017; Peterson & Kramer, 2001)。与传统方法相比,HMM可以从数据中训练每个场景每个被试的ROI及其概率转换信息,既包括静态信息又包括动态信息。本研究发现重复场景搜索速度显著快于新异场景是由于两种场景的眼动模式存在显著的不同。重复场景通常从全局搜索或注视点直接转移到目标上,而新异场景主要是从注视点到全局搜索后转移到目标上。
4.1 目标位置差异对背景线索效应的影响
背景线索效应的内在机制是目标与场景之间的空间联结(Sisk et al., 2019),因此目标的空间位置对背景线索效应有一定的影响。当目标位于搜索界面左上角或右上角时,重复场景的搜索模式为首先进行全局搜索而后对目标进行搜索,而新异场景的搜索模式为从注视点转为全局搜索而后转移到目标上。当目标位于搜索界面左下角时,重复场景和新异场景眼动模式的差异主要在于重复场景中ROI2的初始概率更高。当目标位于搜索界面右下角时,重复场景和新异场景眼动模式的差异主要在于重复场景中ROI1到ROI3的转换概率更高。前人有关背景线索效应灵活性的研究通常采用学习阶段与后测阶段的目标位置重新打乱的方法,结果发现背景线索效应是不灵活的(Preuschhof et al., 2019; Yang et al., 2021; Zinchenko et al., 2022)。但由于目标位置的变化,导致眼动模式也会发生变化,若学习与后测的目标位置在相同象限(如都在左下角),被试的眼动模式不变,是否会出现不同的结果,仍是值得探讨的问题。
4.2 个体差异对背景线索效应的影响
传统的有关背景线索个体差异的研究均是将被试进行人为分组后进行研究。Preuschhof等(2019)采用经典背景线索效应范式研究年轻人与老年人群体之间背景线索效应的差异,结果发现老年人产生背景线索效应的时间显著慢于年轻人。李士一等(2022)同样采用经典背景线索效应范式研究媒体多任务经验对背景线索效应的影响,结果发现高媒体多任务被试存在内隐记忆优势。本研究采用HMM方法,采用数据驱动的方式根据被试的眼动模式将其聚类成两组。结果发现不同的个体存在不同的眼动模式,且这种模式不会随着场景的变化而变化。Zinchenko等(2022)也发现了类似的结果,将视觉搜索任务分为学习和目标位置变化后的测试阶段,将被试分为游戏玩家与非游戏玩家,结果发现游戏玩家与非游戏玩家在测试阶段的表现没有显著差异。
4.3 不同眼动模式对背景线索效应的影响
传统分析背景线索效应的方法通常依赖预定义的兴趣区域或注视点热图,无法充分反映个体在时空维度上的差异。本研究采用数据驱动的隐马尔可夫模型划分兴趣区域,并估计不同兴趣区之间的转移概率,从时空维度上将被试的眼动模式聚类为两种类型:定向搜索模式与全局搜索模式。该结果有助于解决背景线索效应的学习是基于全局(Kunar et al., 2006)的还是基于局部(Zang et al., 2015)的争议。近年研究发现全局和局部的背景线索效应学习并不相互排斥,而是共同起作用(Bergmann & Schubö, 2021)。这些不同结果的产生可能是背景线索效应的学习存在个体差异,一部分人倾向于使用全局搜索模式,其学习效应依赖于全局信息;另一部分人则采用定向搜索模式,其学习效应依赖于局部信息。此外,为探讨搜索模式的差异是否由被试的场认知风格所致,研究者分析了不同认知风格被试在背景线索效应任务中的表现。尽管已有研究结合场认知风格与背景线索效应的实验任务发现,场独立与场依存的被试在任务表现中没有显著差异(金君敏, 2017; 魏玲 等, 2017)。但这种掩蔽效应很可能是由于经验对认知风格的影响,导致被试在重复场景的搜索中掩盖了认知风格的作用(Kim, 2001)。
5 结论
本研究使用眼动技术考察背景线索效应的加工机制及眼动模式的个体差异,结果显示重复场景对目标的搜索快于新异场景,是因为重复场景下被试从注视点转移到目标位置的概率更高或重复场景下采用全局搜索的初始概率更高。被试在搜索任务中存在两种眼动模式,全局搜索与定向搜索,且不会随着场景的变化而变化。