
1 引言
预测加工是语言理解的一个基本特征。在文本阅读中,读者可以基于存储在长时记忆中的知识经验和对当前语境的内部表征(对已加工语境形成的表征,从低水平的亚语音表征到高水平的特定事件、事件结构、篇章水平的表征),对将来的句子内容产生预测,以促进对将来信息的加工,提高阅读效率(Staub, 2015)。通过句子补全任务获得的词汇完型概率(Taylor, 1953),可以作为词汇预测性指标,即在前文语境下给出该词的被试比率(Staub, 2015)。来自英语、汉语和德语的研究均发现,词汇预测性影响阅读时的加工时间和眼跳模式(白学军 等, 2011; 张慢慢 等, 2023; Cui et al., 2022; Kliegl et al., 2004; Liu et al., 2018; Rayner et al., 2005; Rayner & Well, 1996),即词汇预测性效应,个体对高预测词的加工比低预测词更快、跳读率更高、向前眼跳距离更长;其次,高预测词比低预测词的语义整合更加容易,在电生理实验中引起波幅较小的N400成分(Delong et al., 2005; Federmeier & Kutas, 1999; Federmeier et al., 2007; Kutas & Hillyard, 1984)。
虽然以往研究普遍发现了词汇预测性效应,但对于该效应的产生机制还存在一定的争论,主要有两种理论观点。
第一,“语义预测”观点认为(semantic prediction)(Luke & Christianson, 2016),读者基于前文信息和已有知识经验,对可能出现词汇的共同语义特征产生预激活(semantic pre-activation)(Kuperberg & Jaeger, 2016; Luke & Christianson, 2016; Staub, 2015),即预测发生在语义水平。根据该观点,读者在任何给定的语境中都能激活多个词汇(Luke & Christianson, 2016),这并不是说所有可能的词都会被激活,而是同时激活多个最有可能出现的词(Traxler, 2014)。例如,基于句子“讲台上站着一位__ ”,读者可能激活的语义是“老师”“教授”“学生”“班主任”“女生”等,其中“老师”的激活程度可能最高,加工时间最短,而其他词汇的激活逐渐降低,加工时间逐渐延长,表现出渐进性的激活特点。
相关研究通过比较语义相关低预测词和语义无关低预测词的加工差异(语义相关促进效应),对语义预测观点进行了检验(Federmeier & Kutas, 1999; Federmeier et al., 2002; Kutas & Hillyard, 1984)。例如,Federmeier和Kutas采用快速系列视觉呈现范式(RSVP)呈现句子(例如,“They wanted to make the hotel look more like a tropical resort. So along the driveway, they planted rows of palms/pines/tulips.”),操纵句子尾词为高预测词(palms)、和高预测词同一语义类别的低预测词(pines)、无关低预测词(tulips),结果发现相比于无关低预测词,语义类别一致的低预测词引起波幅较小的N400成分,说明了语义重叠的促进效应,支持了语义预测。其次,一些研究考察语境限制性对非预测词的加工是否存在预测错误损失(李琳 等, 2022; Frisson et al., 2017),即相比于弱限制性语境,强限制性语境下加工预测性相同的非预测词是否需要额外的认知负荷,结果在N400波幅和眼动指标上没有发现该损失(赵赛男 等, 2021; Chang et al., 2023; Federmeier et al., 2007; Frisson et al., 2017),也支持了语义预测观点。此外,词汇预测性和阅读时间(Brothers & Kuperberg, 2021; Luke & Christianson, 2016)以及N400波幅(Frank et al., 2015)存在负相关,间接支持语义预测。
第二,“词汇预测”观点认为(lexical prediction)(Staub, 2015),读者基于长时记忆中存储的语义知识和对前文语境的内部表征,对某个特定的词产生预测,也称为全或无(all-or-none)的词汇预测。如果实际出现的词和预测词一致,则产生预测正确的促进效益,如果不一致,则需要抑制已经激活的预测词,加工实际出现的非预测词,进而使加工时间延长,产生预测错误损失(李琳 等, 2022)。根据该观点,读者在一个语境中一次只预测一个最可能的词,即完型概率最高的词,其他词为非预测词,读者对非预测词的加工没有差异。
已有研究为词汇预测观点提供了实证支持(Bonhage et al., 2015; Carter et al., 2019; Schuster et al., 2015),但词汇水平的预测可能依赖于一定的条件。例如,Federmeier等人(2007)操纵语境限制性强、弱,目标词为预测词、非预测词(非预测词和预测词语义不相关但适合语境),采用RSVP范式呈现句子,考察语境限制性对词汇加工的影响。发现在N400指标上未出现预测错误损失,支持语义预测;但在500~900 ms时间窗,强限制性语境的非预测词引起晚期额叶正波,说明了可能的预测错误信号或预测错误损失,结果支持词汇预测。但需要谨慎解释这个看似矛盾的结果:N400波幅反映了语境信息对语义特征或概念的促进,即语义预测;晚期额叶正波可能反映了预测错误损失,也可能仅代表预测错误的信号,该电生理信号传递到高级皮层,以更新对当前语境的表征,但不会反映在阅读时间上(Frisson et al., 2017)。如果晚期额叶正波代表预测错误损失,那么这可能和刺激呈现方式有关,RSVP范式减慢了阅读速度,使读者产生具体的词汇预测;也可能和语境限制性有关,强限制性语境提供丰富的语境信息,促进了预测加工。此外,Ito等人(2016)操纵句子尾词为预测词、词形相关非预测词、语义相关非预测词、无关词,并操纵SOA为500 ms或700 ms,发现仅在SOA为700 ms且强限制性的语境中,词形相关词引起的N400波幅才小于无关词,说明了刺激呈现速度和语境限制性影响预测加工。
综上,英语阅读中语义预测得到较多研究的一致支持,词汇预测的产生依赖于强限制性语境。然而,对汉语预测加工的研究还比较缺乏。目前,仅有两项汉语研究采用和Frisson等人(2017)类似的实验,未发现预测错误损失(赵赛男 等, 2021; Chang et al., 2023),支持语义预测。赵赛男等人的实验1未出现预测错误损失,原因可能是强限制性语境中的低预测词和高预测词存在语义相关,促进了对低预测词的加工,使预测错误损失消失;实验2为了排除语义相关造成的干扰,采用语义违背范式,低预测词是和高预测词语义无关的不可预测词,结果仍未发现预测错误损失。说明了汉语阅读中的预测加工主要是语义预测而非词汇预测。不存在预测错误损失是语义预测的证据之一,语义相关促进效应也是关键特征(Federmeier & Kutas, 1999; Kutas & Hillyard, 1984; Roland et al., 2012)。以往研究从预测错误损失角度检验语义预测观点(赵赛男 等, 2021; Chang et al., 2023),本研究在此基础上考察汉语阅读中是否存在语义相关促进效应,进一步考察预测性效应的机制。
英语和汉语在语言结构和语法规则上存在一定差异,因此英语研究结果不能直接推论到汉语阅读中。英语注重语法规则,依靠各种连接手段实现语言结构的完整性,例如表示逻辑关系的连接词(and, but, so, however)、关系词(that, which, what, how, where)、介词(of, in, on, about)、冠词(a, an)等,a/an为随后的词汇提供语音信息。英语词汇也有较丰富的形态变化,如动词be的多种形态(am, is, are, was, were, been, being)表示不同的语法意义,为随后的词汇提供单复数、时态、大小写等语法信息,读者可以利用这些信息产生较高程度的预测。而汉语是语义型语言,句子成分之间的辅助词要少很多,主要靠实词的本身意义和语序连接起来,词汇也缺少形态变化。这些特征可能使汉语的语境限制性较弱,词汇预测性较低,例如北京句子语料库中词汇的平均预测性为0.07(Pan et al., 2021),远低于Provo语料库(0.13)(Luke & Christianson, 2016)。因此,本研究推测,阅读汉语时主要发生语义水平的预测,而较难发生词汇水平的预测。
基于以上,本研究通过句子阅读实验考察汉语阅读中的预测加工是否表现出渐进性的特点,以检验“词汇预测”或“语义预测”观点的合理性。为此,本研究采用句子完型任务,选取一个高预测词和三个完型概率相同的低预测词。在前人研究中,低预测条件通常包含两个水平(Federmeier & Kutas, 1999; Kutas & Hillyard, 1984);为了证明预测的渐进性特点,本研究将低预测条件设为三个水平。通过潜在语义分析方法计算高预测词与低预测词之间的语义相似度(Günther et al., 2016),根据语义相似度高低,将低预测词设置为L1、L2、L3条件。根据语义预测观点,预测应表现出渐进性特点,即读者在阅读中预激活符合语境的语义特征,具有该语义特征的词会得到不同程度的激活,因此,和高预测词语义特征接近的词,其加工时间应该更短(L1<L2<L3)、跳读率更高(L1>L2>L3),即语义相似度效应显著。反之,根据词汇预测观点,读者只激活一个高预测词,那么对预测性相同的低预测词的加工时间和跳读率应无显著差异,无语义相似度效应。
此外,根据前人研究(Federmeier et al., 2007; Ito et al., 2016)可推测,语境限制性是影响预测的一个关键因素,语境限制性较弱,则只能产生语义水平的预测,语境限制性越强,越容易产生词汇水平的预测。因此,本研究也分析语境限制性是否调节预测加工。研究预期,随着语境限制性的增强,促进产生词汇水平的预测,因而语义相似度效应降低,词汇预测性效应增大。
2 研究方法
2.1 被试
由于实验设计同时存在被试和项目变异,因此,通过在线统计功效计算程序PANGEA计算样本量(Westfall, 2016)。采用默认的效应量d=0.45,α为0.05,双尾检验。结果显示,在当前80组材料的情况下,达到80%以上的统计功效需要48人。由于数据预处理需要删除一些数据,因此研究招募80名大学生(平均年龄20.5岁,女性73人)参与实验。被试裸视或矫正视力正常,使用Tumbling E视力表测得视敏度均优于20/40,视觉对比度优于1.64。所有被试均为汉族,母语为汉语,自愿参与实验,在实验前完全了解实验程序并签署知情同意书。
2.2 实验设计
在同一个句子中设置一个高预测词(H)和三个预测性相同的低预测词(L1、L2、L3),操纵低预测词与高预测词之间的语义相似度由高到低排序(L1>L2>L3)。见表1 ,“困难”是高预测词,三个低预测词与“困难”之间的语义相似度排序为:问题>挑战>任务。
表1 实验材料举例 |
| 条件 | 句子 |
| 高预测词H | 救援队当前面临的困难是如何移动受伤的游客。 |
| 低预测词L1 | 救援队当前面临的问题是如何移动受伤的游客。 |
| 低预测词L2 | 救援队当前面临的挑战是如何移动受伤的游客。 |
| 低预测词L3 | 救援队当前面临的任务是如何移动受伤的游客。 |
注:目标词以粗体显示,实验中正常显示。 |
2.3 实验材料
招募20名大学生参与句子补全任务,最终选取符合实验设计的80个句子,目标词信息见表2 。通过潜在语义分析方法(Günther et al., 2016),基于腾讯AI实验室的中文词向量数据集(Song et al., 2018)计算低预测词与高预测词之间的语义相似度。该方法是一种自然语言处理技术,即训练大型语料库,使用数学中的向量表示文本,获得预训练的词向量数据集,以两个词向量的余弦夹角衡量它们之间的语义相似度,向量的夹角越小,距离越近,词汇越相似,因此也称为余弦相似度、语义空间距离。目前,已有较多研究使用该方法计算词汇之间的语义相似度(Roland et al., 2012; Yun et al., 2012)。语义相似度平均值见表2 ,范围分别为L1[0.37, 0.89]、L2[0.32, 0.82]、L3[0.24, 0.78],此外,高预测词与其自身的语义相似度为1。L2与H的语义相似度显著小于L1[t(158)=6.27, p<0.001],L3与H的语义相似度显著小于L2[t(158)=6.42, p<0.001]。
表2 目标词信息的平均值和标准差[M(SD)] |
| 高预测词(H) | 低预测词1(L1) | 低预测词2(L2) | 低预测词3(L3) | |
| 预测性 | 0.83(0.15) | 0.03(0.04) | 0.02(0.03) | 0.02(0.04) |
| 句子通顺性 | 5.26(0.50) | 5.26(0.44) | 5.25(0.45) | 5.18(0.40) |
| 词频 | 3.04(0.67) | 2.61(0.85) | 2.64(0.84) | 2.54(0.77) |
| 首字字频 | 4.19(0.57) | 4.17(0.61) | 4.13(0.65) | 4.13(0.61) |
| 尾字字频 | 4.12(0.57) | 4.22(0.64) | 4.03(0.83) | 4.17(0.64) |
| 整词笔画数 | 16.25(4.44) | 16.83(4.29) | 16.88(4.83) | 15.85(4.85) |
| 首字笔画数 | 8.00(2.60) | 8.34(2.99) | 8.78(3.12) | 7.71(3.33) |
| 尾字笔画数 | 8.25(3.02) | 8.49(3.18) | 8.10(3.17) | 8.14(3.40) |
| 语义相似度 | 1.00(0.00) | 0.69(0.11) | 0.58(0.11) | 0.47(0.11) |
对无关变量的控制:(1) L1、L2、L3的预测性主效应不显著(p=0.20);(2)基于电影字幕语料库查找词频和字频(Cai & Brysbaert, 2010),L1、L2、L3的词频主效应不显著(p=0.39),首字字频(p=0.90)和尾字字频(p=0.37)在四个条件下差异不显著;(3)四个条件的整词笔画数(p=0.44)、首字(p=0.14)和尾字笔画数(p=0.87)主效应不显著;(4)基于拉丁方方法将材料分为4组,每组12人,共48名大学生对句子通顺性进行七点评估(“1”代表“十分不通顺”,“7”代表“十分通顺”),结果显示,通顺性主效应不显著(p=0.61)。参与句子补全任务和通顺性评估的大学生不参与阅读任务。
2.4 实验仪器和程序
采用SR Research公司的EyeLink 1000 Plus眼动仪记录被试阅读句子时右眼的眼动轨迹,仪器采样率为1000 Hz,显示器分辨率为1920×1080像素,刷新率为60 Hz。句子以32号黑色宋体呈现在灰色(RGB: 192, 192, 192)背景上。被试眼睛距离屏幕大约65 cm,每个汉字约占1°水平视角。
采用拉丁方设计将实验句子分到4个组中。每组包括相同的6个练习句和20个填充句。被试被随机分配到某个组中参与阅读实验,每个组20名被试。(1)测量视敏度和视觉对比度,签署知情同意书。(2)主试讲解指导语,要求被试按照平时的习惯进行默读。(3)进行三点水平校准,校准误差最大值和平均值均小于0.3°。(4)被试先阅读6个练习句,熟悉程序后进入正式实验。在句子呈现之前,句子首字位置出现一个注视点“+”,被试需要准确注视“+”,句子才能呈现,阅读完之后按空格键结束该句。在25%的实验句后跟随一个相关的理解性问题,被试需要做出“是”或“否”的判断并按键反应(回答“是”按“F”键,“否”按“J”键),以检验被试是否认真阅读。实验用时约30分钟。
3 结果
80名被试回答问题的正确率平均值为88%(SD=5%),说明被试认真阅读了句子。数据预处理包括:(1)导出数据时的clean程序删除注视点小于140 ms、大于800 ms的注视点;(2)删除实验过程中受到干扰的试次(头动、咳嗽等);(3)删除句子上注视点个数少于6的试次。一共删除359个试次,占比6%。对余下数据使用R软件中的lme数据包(Bates et al., 2015)进行线性混合效应模型分析。采用MASS包(Venables & Ripley, 2002)中的contr.sdif函数进行数据对比。t和z值大于1.96代表效应显著。
分析以下指标:跳读率、首次注视时间(FFD)、单一注视时间(SFD)、凝视时间(GD)、回视路径阅读时间(RPD)和总注视时间(TRT)。描述性统计结果见表3 。
表3 目标词眼动指标的平均值和标准误[M(SE)] |
| 高预测词(H) | 低预测词1(L1) | 低预测词2(L2) | 低预测词3(L3) | |
| 跳读率(%) | 37(1) | 31(1) | 33(1) | 34(1) |
| 首次注视时间(ms) | 242(3) | 247(3) | 245(2) | 256(3) |
| 单一注视时间(ms) | 240(3) | 245(3) | 244(3) | 255(3) |
| 凝视时间(ms) | 258(4) | 271(4) | 278(4) | 282(4) |
| 回视路径阅读时间(ms) | 312(8) | 330(7) | 335(8) | 349(9) |
| 总注视时间(ms) | 322(6) | 345(6) | 355(6) | 365(7) |
3.1 词汇预测性效应
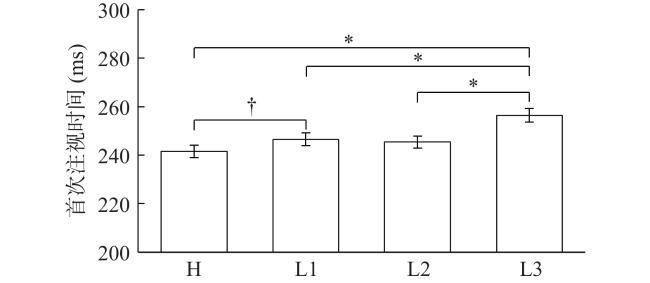
分别对高预测词与L1、L2、L3进行比较分析,见图1 。在跳读率上词汇预测性效应显著(H>L1: b=−0.31, SE=0.08, z=−3.75; H>L2: b=−0.20, SE=0.08, z=−2.48; H>L3: b=−0.19, SE=0.08, z=−2.40)。在FFD、SFD上,高预测词的注视时间短于L3(FFD: b=0.05, SE=0.01, t=4.13; SFD: b=0.05, SE=0.01, t=4.29),但和L1、L2没有显著差异(|t|s<1.78)。在GD、RPD、TRT上,高预测词的注视时间短于L1(GD: b=0.04, SE=0.02, t=2.77; RPD: b=0.06, SE=0.02, t=2.91; TRT: b=0.08, SE=0.02, t=4.08)、L2(GD: b=0.05, SE=0.02, t=3.54; RPD: b=0.06, SE=0.02, t=2.85; TRT: b=0.09, SE=0.02, t=5.00)和L3(GD: b=0.02, SE=0.02, t=4.67; RPD: b=0.10, SE=0.02, t=4.93; TRT: b=0.11, SE=0.02, t=6.13)。结果说明,词汇预测性效应发生在词汇加工的早期和晚期阶段。
3.2 语义相似度效应
研究主要考察,对于预测性相同的三个低预测词,是否由于与高预测词之间的语义相似而加工更快,即语义相似度效应。结果显示,L1、L2、L3的跳读率逐渐提高,但未达到显著水平;L1、L2、L3的注视时间逐渐延长。具体来说:(1) L2的加工时间长于L1,在RPD上显著(b=0.04, SE=0.02, t=2.10),但在FFD、SFD、GD上不显著(|t|s<0.81);(2)相比于L2,L3在FFD(b=0.04, SE=0.01, t=3.14)、SFD(b=0.04, SE=0.01, t=2.87)和RPD(b=0.04, SE=0.02, t=2.12)上显著更长,但在GD和TRT上(|t|s<1.20)无显著差异。重新设置比较矩阵,比较L1和L3的加工差异,发现L3在时间指标上都显著更长(FFD: b=0.03, SE=0.01, t=2.62; SFD: b=0.03, SE=0.01, t=2.57; GD: b=0.03, SE=0.01, t=1.97; RPD: b=0.04, SE=0.02, t=2.10; TRT: b=0.04, SE=0.02, t=2.11)。
结果显示:在控制了词汇预测性之后,低预测词和高预测词之间的语义相似度越低,对低预测词的加工时间越长。
3.3 语境限制性对预测加工的影响
考虑到语境限制性对预测加工的潜在影响,即强限制性语境提供了更多的语境信息,减少了可能的词汇候选项,从而提高了预测的准确性,促进产生词汇水平的预测;相反,弱限制性语境中语境信息较少,预测的难度增加,更可能产生语义水平的预测。因此,为分析语境限制性对预测加工的影响,研究根据Yun等人(2012)的建议计算语境限制性,即采用信息论中的标准度量—熵(heat function, H)来衡量语境限制性,见公式1。
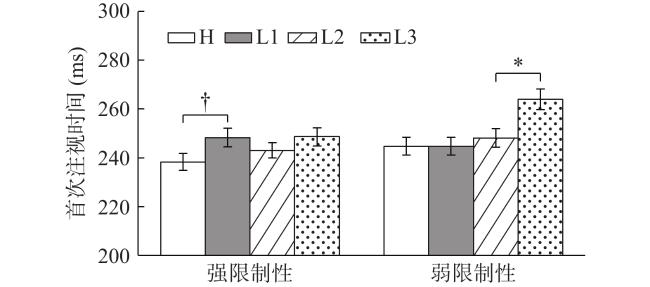
首先,语境限制性×词汇预测性(H vs. L1)的交互在FFD、GD、TRT上显著(FFD: b=1.85, SE=0.80, t=2.40; GD: b=2.22, SE=0.97, t=2.29; TRT: b=2.79, SE=1.19, t=2.35)。交互效应表现为:强限制性语境下的词汇预测性效应更大(FFD: b=−0.03, SE=0.02, t=−1.81; GD: b=−0.05, SE=0.02, t=−2.26; TRT: b=−0.08, SE=0.03, t=−3.06),而在弱限制性语境下不显著或更小(FFD, GD: |t|s<1.65; TRT: b=−0.07, SE=0.03, t=−2.69),见图2 。说明了在强限制性语境下,读者对高预测词产生特定的词汇预测,而意料之外的低预测词偏离高预测词,进而高、低预测词加工时间差异较大;弱限制性语境的信息量较少,读者对将来信息产生语义预测,低预测词的语义特征没有显著偏离高预测词,进而对H和L1的加工差异较小。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
其次,语境限制性×语义相似度(L2 vs. L3)的交互在时间指标上均显著(FFD: b=0.06, SE=0.03, t=2.38; SFD: b=0.07, SE=0.03, t=2.46; GD: b=0.07, SE=0.03, t=2.08; RPD: b=0.09, SE=0.04, t=2.07; TRT: b=0.08, SE=0.04, t=2.16)。表现为在弱限制性语境下语义相似度效应显著(FFD: b=−0.06, SE=0.02, t=−3.49; SFD: b=−0.06, SE=0.02, t=−3.34; GD: b=−0.04, SE=0.02, t=−2.00; RPD: b=−0.08, SE=0.03, t=−2.54; TRT: b=−0.05, SE=0.03, t=−2.07),而在强限制性语境下,语义相似度效应均不显著(|t|s<0.87),见图2 。该交互效应和Yun等人(2012)的研究结果一致,说明弱限制性语境下更可能发生语义水平的预测,读者对可能出现的语义特征产生一般性的预激活,高相似度的词汇得到更高程度的激活;而强限制性语境下,预测具体到某个特定的词汇,因而未出现语义相似的促进效应。
此外,语境限制性和L1与L2的对比交互不显著(|t/z|s<1.65),其原因可能是L1和L2的语义相似度差异较小。
4 讨论
本研究操纵低预测词和高预测词之间的语义相似度,考察预测过程是否表现出渐进性的特点,以验证读者是产生特定的词汇预测还是语义预测。结果发现,语义相似度越高,个体对低预测词的加工时间越短。这表明语义相似度高,词汇激活程度高,读者对将来信息产生渐进性的语义预测。此外,语境限制性调节预测加工,强限制性语境下语义相似度效应降低,原因可能是丰富的语境信息促进了词汇水平的预测。
语义相似度效应体现了预测的渐进性特点,这为语义预测假说提供了关键证据。研究操纵语义相似度条件L1、L2、L3,虽然L1的加工快于L3,L2的加工快于L3,但L1与L2的差异仅在回视路径阅读时间上显著。L3和L2的差异在首次、单一注视时间和回视路径阅读时间上显著,而在凝视时间和总注视时间上不显著。L3在早期和晚期加工时间上均快于L1。此外,在跳读率上没有发现语义相似度效应。整体而言,语义相似度效应显著。
语义预测的关键证据包括:强限制性语境下加工低预测词不存在预测错误损失(李琳 等, 2022; Frisson et al., 2017),以及语义相似促进效应(Federmeier & Kutas, 1999; Kutas & Hillyard, 1984)。已有汉语研究未发现显著的预测错误损失(赵赛男 等, 2021; Chang et al., 2023),支持了语义预测假说。本研究基于语义相似促进效应,进一步验证了语义预测假说。具体而言,在阅读时读者对可能出现词汇的语义信息产生渐进性的预激活,已经被激活的语义表征通过扩散激活的方式,促进对具有相同或相似语义表征的目标词的激活(McRae et al., 1997)。因此,和高预测词语义相似的低预测词在心理词典中获得较高的激活水平,从而促进了加工。本研究结果与英语研究结果一致,表明阅读过程中语义预测机制具有跨语言的一致性(Kuperberg & Jaeger, 2016)。这种跨语言一致性进一步说明了语义预测在语言理解中的重要作用。
此外,英语阅读的脑电研究显示,语境限制性可能影响预测加工,语境限制性越强,越可能促进产生词汇水平的预测(Federmeier et al., 2007; Ito et al., 2016)。为分析语境限制性的影响,本研究将语境限制性分为强、弱两水平,发现语境限制性对语义相似度效应具有调节作用,这和英语研究结果一致(Günther et al., 2016; Pynte et al., 2008; Roland et al., 2012)。具体而言,强限制性语境条件下的语义相似度效应小于弱限制性语境,而强限制性语境下的词汇预测性效应更加显著。这可能是由于阅读中的预测加工依赖语境限制性而变化。强限制性语境促进产生具体的词汇预测,如果目标词是高预测词,则符合预期,加工时间较短,而当目标词是低预测词时,较大程度地偏离高预测词(相比于弱限制性语境),加工时间延长,因而词汇预测性效应更大。相反,在弱限制性语境中,读者激活可能出现词汇的共同语义表征,因此,当目标词和预期不符时,如果目标词和高预测词具有较高程度的语义相似性,则已经被激活的语义特征通过扩散激活的方式,促进对目标词的加工,进而表现出语义相似度效应。
需要注意的是,在日常语言环境中,强限制性语境很少出现(Huettig & Mani, 2016)。例如,对汉语句子语料库的统计发现(Pan et al., 2021),词汇完型概率平均值仅为0.07,说明汉语文本普遍具有较弱的语境限制性。本研究采用了较强限制性的句子,存在鼓励预测或促进词汇预测的倾向,但仍然发现语义相似度效应显著。因此,在弱限制性语境更加普遍的日常语言环境中,更可能产生语义水平的预测。基于以上,汉语阅读中预测加工普遍发生在语义水平,但本研究并未完全否定词汇水平的预测,其发生依赖于强限制性语境。
最后,根据汉语阅读的眼动控制模型(CRM)(Li & Pollatsek, 2020),词频、预测性和复杂性是影响词汇加工的关键变量。当前研究在控制低预测词的词频、预测性、复杂性的前提下发现语义相似度效应,说明词汇加工负荷不仅受到这些因素的影响,还受到该词和未出现词汇之间语义相似度的影响。因此,在模拟词汇加工时还需考虑可能出现的其他词汇。
5 结论
研究操纵低预测词和高预测词之间的语义相似度,发现:(1)语义相似度效应显著,体现出渐进性的语义预激活特点,支持了“语义预测”观点;(2)语境限制性调节预测过程,强限制性语境促进“词汇预测”的产生。