
1 引言
人工智能(artificial intelligence, 以下简称AI)在人类社会中扮演的角色愈发接近人类(周详 等, 2024),相关伦理问题逐渐显现(Obermeyer et al., 2019),AI能否做道德决策就是焦点问题之一。尽管人们反对AI进行道德决策(Bigman & Gray, 2018),但是研究也发现,人们更容易接受AI的不道德决策(Wilson et al., 2022),而不是人类的。研究者应该重视这种道德判断的不对称性,以避免AI成为不道德行为的最佳代理。
上述不对称性一方面表现为对AI违反道德的宽容。以违反道德为背景的研究发现,人们对违反道德的AI产生更少的责备、道德愤怒与道德惩罚欲(许丽颖 等, 2022; Bigman et al., 2023; Maninger & Shank, 2022)。心智感知是道德判断的前提(Gray & Wegner, 2012),它包含能动性与体验性两个维度(Gray et al., 2007),AI作为算法具有一定的能动性但缺乏体验性(Brink et al., 2019),人们认为其不具备独立的心智,无法承担道德责任(Bonaccio & Dalal, 2006),对其道德错误表现得更为宽容(Ayad & Plaks, 2025)。正如Wilson等人(2022)发现,个体并不会将AI违反道德解读为一个道德问题,而是一种算法的性能缺陷。
这种不对称性另一方面表现为对AI功利性选择的赞许。采用经典道德两难范式的研究发现,相比于人类,人们更期望AI做出功利性决策(Malle et al., 2025; Myers & Everett, 2025),并认为AI的功利性决策要比人类的更加道德(Chu & Liu, 2023; Komatsu et al., 2021)。计算机作为社会参与者理论认为,个体会无意识地将社会规则应用到计算机上(Nass & Moon, 2000),将AI当作社会成员(Xu et al., 2022),对其产生社会认知。温情和能力是社会认知的两个重要维度(Fiske et al., 2007),研究发现人们预测高能力−低温情的人更有可能做出功利性决策(Rom et al., 2017),AI被感知为高能力−低温情(Liu et al., 2021),因此人们往往预测AI会做功利性选择,Zhang等人(2022)发现,感知温情在其中发挥中介作用。
上述道德判断不对称性是AI自身的算法身份还是它引起的社会认知造成,经典道德两难范式无法进行区分,因为它预设了功利性倾向与道义性倾向处在跷跷板的两端,一方的上升必定引起另一方同等程度的下降,掩盖了双加工理论对二者相对独立的预设(Greene et al., 2001),无法对两种选择倾向进行单独量化(徐科朋 等, 2020)。若将二者进行单独量化,便可以对这种道德判断不对称的原因进一步深入:如果人们将AI当作算法,只会要求其尽可能功利,以保证收益最大化,不会要求其像人类一样遵守道义,因为算法不是社会参与者;如果人们将AI当作社会参与者,便会要求其像人类一样遵守道义,同时由于AI被感知为高能力−低温情,人们也会要求其功利。
道德判断的CNI模型对道德困境判断的心理过程进行更为精细的划分,能够对功利性倾向与道义性倾向进行单独量化(Gawronski et al., 2017),该模型认为道德判断受到3个因素影响:对结果收益的敏感性(C, Consequences),对道德规范的敏感性(N, moral Norms),以及个人的不行动/行动偏好(I, Inaction versus action),如图1 所示。其中C参数与N参数分别对应功利性倾向与道义性倾向,因此,观察两个参数的变化,便能够分析人们对AI的角色认知。机器启发式(machine heuristic)指人们对机器的刻板印象,认为机器比人类更加理性高效(Sundar & Kim, 2019),AI的本质就是一种算法,不具有社会地位,所以不需要像人类一样遵守道德规范,但由于机器启发式,人们可能认为AI的道德推理更加理性公正,因此更容易接受其功利性建议(Aharoni et al., 2024; Fabre et al., 2024)。本研究提出假设1:相较于人类,人们对AI道德选择的结果收益更敏感,对是否遵守道德规范更不敏感,在CNI模型中表现为C参数更大,N参数更小。
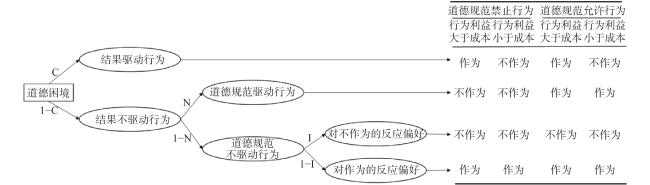
图1 道德决策CNI模型工作路径图(Gawronski et al., 2017) |
拟人化可能会提高人对AI的社会认知,促进人们对AI的道德要求向人类靠拢。拟人化是将人类的外表特征、动机、意向或心理状态赋予非人类(许丽颖 等, 2017)。研究显示,拟人化能够提高人们对AI产品的感知温情(Bai et al., 2024),而温情是社会认知的维度之一(Fiske et al., 2007),许丽颖等人(2022)发现,算法做出歧视决策后,人们对拟人化程度高的算法表现出更强的道德惩罚欲。因此提出假设2:相较于低拟人化AI,人们对高拟人化AI的道德选择是否遵守道德规范更敏感,在CNI模型中表现为N参数更大;假设3:感知温情在AI拟人化与道德规范敏感性(N参数)之间发挥中介作用。
2 研究1:身份信息(人类 vs. AI)对道德困境判断的影响
研究1探究在道德困境中个体对人类与AI选择的判断差异,由实验1a、1b两个实验构成,实验1a使用原版道德困境判断材料(Gawronski et al., 2017),初步验证道德判断差异之存在,实验1b使用扩展版道德困境判断材料(Körner et al., 2020),对个体差异进行控制后检验实验1a结果的稳健性。
2.1 实验1a
2.1.1 被试
在Credamo平台招募被试,实时剔除未通过注意力检测者,最终获得194名有效被试。男性104人(53.61%),女性90人(46.39%),平均年龄24.57±5.33岁,大部分(82.00%)拥有本科学历。
2.1.2 实验材料
原版道德困境判断材料。采用Gawronski等人(2017)编制的道德困境材料,包含6种道德困境故事,每种有4个版本,共24个道德场景。问卷中设置注意力检查任务,回答错误者的数据将被剔除。
2.1.3 研究设计与程序
采用单因素被试间设计。被试在阅读并签署知情同意后,被随机分配至人类组或AI组。以姓氏和字母(周某/GX-11)区分人类与AI。24个场景以完全随机顺序呈现,被试判断(接受/不接受)每个场景中主人公的选择,最后,填写人口学信息,包括性别、年龄与学历。
2.1.4 数据分析
CNI模型是多项式加工树模型。使用multiTree (Moshagen, 2010)软件对被试的C、N、I参数进行估算。使用拟合优度G2来评估模型与数据之间的匹配程度。G2值不显著(p>0.05),说明数据与模型之间拟合良好。若C参数和N参数的95%置信区间不包含0,I参数的95%置信区间不包含0.5,说明C、N、I所代表的心理过程显著影响被试的道德判断。本研究中,I参数显著大于0.5表明被试偏好拒绝人类/AI的选择,反之,更偏好接受。比较不同群体时,使用ΔG2值作为检验指标,若ΔG2值显著(p<0.05),说明群体间CNI参数存在显著差异。
将被试的“接受”选项编码为1,“不接受”选项编码为0,分别计算每组被试四种条件(图1 )下接受/不接受的频次。使用Gawronski等人(2017)的multiTree模板对两组数据进行差异检验。
2.1.5 结果
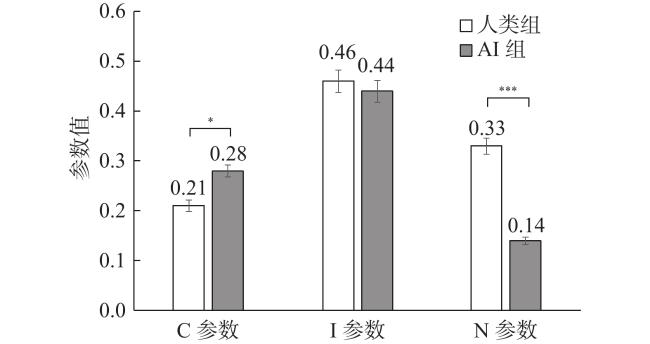
人类组与AI组被试均为97人。两组数据同时进行CNI模型拟合,G2(2)=3.82,p=0.148,大于0.05,模型拟合良好。C、N、I参数估计值见表1 。两组被试的C、I参数差异均不显著[ΔG2(1)=1.26, p=0.262; ΔG2(1)=0.15, p=0.699],N参数差异显著[ΔG2(1)=6.09, p=0.014]。
表1 人类组与AI组被试的CNI参数与95%置信区间 |
| 组别 | C参数 | N参数 | I参数 | |||||
| M | 95%CI | M | 95%CI | M | 95%CI | |||
| 人类组 | 0.19 | [0.155, 0.232] | 0.19 | [0.133, 0.227] | 0.33 | [0.295, 0.355] | ||
| AI组 | 0.22 | [0.184, 0.262] | 0.09 | [0.045, 0.143] | 0.33 | [0.288, 0.345] | ||
2.2 实验1b
2.2.1 被试
在Credamo平台招募被试,实时剔除未通过注意力检测者,获得150名有效被试。男性55人(36.67%),女性95人(63.33%),平均年龄25.25±4.65岁,大部分(81.30%)拥有本科学历。
2.2.2 实验材料
(1)道德困境判断材料
采用Körner等人(2020)扩展的道德困境材料,增添了6种道德困境。包含48个道德场景,可用于估算个体的CNI参数。通过指导语“张某是一名成年人”与“RT2000是一款人工智能”区分身份,道德场景使用文字形式呈现,其后跟随一个题目,询问被试对主人公选择的判断(接受/不接受)。
(2)算法熟悉度量表
不同被试对AI的熟悉、了解与喜爱程度可能会影响实验结果,将三者作为控制变量进行测量。采用许丽颖等人(2022)使用的量表。包含3个条目“你对AI有多熟悉?”“与普通中国人相比,你认为你对AI有多了解?”“你有多喜欢AI?”采用7点计分,分数越高,表明被试对AI的熟悉、了解与喜爱程度越高。
注意力检测问卷与人口学问卷同实验1a。
2.2.3 研究设计与程序
采用单因素被试间设计。被试在阅读并签署知情同意后,被随机分配至人类组或AI组,48个道德场景以完全随机的方式呈现,被试阅读后,对主人公的选择进行判断(接受/不接受),最后,填写算法熟悉度量表和人口学量表。
2.2.4 数据分析
使用Körner等人(2020)的multiTree模板对被试的C、N、I参数进行计算。随后将数据导入SPSS25.0进行分析,采用独立样本t检验分析两组被试之间的C、N、I参数的差异,在t检验显著的基础上,对性别、年龄、学历和算法熟悉度进行控制,采用协方差分析进一步验证结果的稳健性。
2.2.5 结果
人类组被试77人,AI组被试73人。独立样本t检验结果显示,人类组被试的C参数显著低于AI组[t(148)=−2.56, p=0.012, Cohen’s d=0.42];前者的N参数显著高于后者[t(148)=4.58, p<0.001, Cohen’s d=0.78]。I参数无差异[t(148)=0.58, p=0.562]。上述结果表明,相比于人类,被试在判断AI的道德选择时,对结果收益更敏感,对道德规范更不敏感,见表2 。
表2 人类组与AI组被试的CNI参数差异检验 |
| 分组 | t | p | Cohen’s d | ||
| 人类组(n=77) | AI组(n=73) | ||||
| C参数 | 0.21±0.17 | 0.28±0.21 | −2.56 | 0.012 | 0.42 |
| N参数 | 0.33±0.29 | 0.14±0.19 | 4.58 | <0.001 | 0.78 |
| I参数 | 0.46±0.19 | 0.44±0.13 | 0.58 | 0.562 | 0.12 |
为进一步检验结果的稳健性,以组别为自变量,性别(男=1, 女=2),年龄,学历,对AI的熟悉、了解和喜爱程度为协变量进行协方差分析,结果显示,在C参数[F(1, 142)=5.63, p=0.024, η$ _{\mathrm{p}}^{2} $ =0.04]与N参数[F(1, 142)=3.97, p<0.001, η$ _{\mathrm{p}}^{2} $ =0.13]上,组别效应均显著,假设1成立。参数差异如图2 所示。
3 研究2:AI拟人化(高 vs. 低)对道德困境判断的影响与机制
研究2通过操纵AI的拟人化程度,探讨被试对高/低拟人化AI在道德困境中选择的判断差异,以及感知温情的中介作用。
3.1 研究方法
3.1.1 被试
在Credamo平台招募被试,实时剔除未通过注意力检测者,获得208名有效被试。男性117人(56.25%),女性91人(43.75%),平均年龄26.64±6.11岁,大部分(78.80%)拥有本科学历。
3.1.2 实验材料
(1)拟人化材料
参考许丽颖等人(2022)文字操纵拟人化的方式,同时结合图片对AI拟人化程度进行操纵,指导语如下:“我叫极智,是一种新型的AI。我可以看懂、听懂人类的各种语言······我是自主性智能助手······”(图3 右);“代号RT2000,是一种新型的AI。RT2000可以分析图片或文字形式的各种人类语言······RT2000是自动化辅助系统·····”(图3 左)。

(2)拟人化感知量表
使用Ferrari等人(2016)编制的拟人化量表,包含3个条目:“我容易弄混极智(RT2000)与真正的人”;“极智(RT2000)看起来像人类”;“我觉得极智(RT2000)看起来与人类很相似”。采用7点计分,1表示“非常不同意”,7表示“非常同意”,总分越高表明被试感知到的拟人化程度越高,研究中Cronbach’s α系数为0.86。
(3)刻板印象内容量表
使用Aaker等人(2012)编制的刻板印象内容量表,分为感知能力与感知温情分量表,各有3个题目,采用7点计分,1表示“非常不同意”,7表示“非常同意”,分数越高表明被试对AI的感知能力、温情越高。感知能力题目为:“我认为极智(RT2000)是能干的/有效的/有能力的”,研究中Cronbach’s α系数为0.61,当题目数小于6个时,内部一致性系数大于0.6,说明量表可靠(Onwuegbuzie & Daniel, 2002)。感知温情题目为:“我认为极智(RT2000)是友善的/好心的/乐于助人的”,研究中Cronbach’s α系数为0.89。
(4)道德困境判断材料同实验1b,用图片结合文字形式呈现AI的选择,其后为选择题目,询问被试是否接受AI的选择。
(5)其他控制变量的测量
机器启发式,测量个体对AI的刻板印象。采用Banks等人(2021)的机器启发式量表,包含6个条目:“我认为极智(RT2000)是客观的/有条理的/高效的/准确的/有逻辑的/可靠的”,采用7点计分,1表示“非常不同意”,7表示“非常同意”,总分越高表明机器启发式水平越高,研究中Cronbach’s α系数为0.76。算法熟悉度量表、注意力检测问卷与人口学问卷同实验1b。
3.1.3 研究设计与程序
采用单因素被试间设计。被试阅读并签署知情同意后,被随机分配至高拟人化AI组或低拟人化AI组阅读关于AI的文字介绍与图片,填写机器启发式问卷与刻板印象内容量表,随后阅读48个道德场景(随机呈现),对AI的选择进行判断(接受/不接受),最后,填写对AI的熟悉、了解、喜爱程度问卷,以及人口学信息,包括性别、年龄与学历。
3.1.4 数据分析
使用Körner等人(2020)的multiTree模板对每个被试的C、N、I参数进行计算。随后将数据导入SPSS25.0进行分析,首先对机器启发式、感知能力与温情、C、N、I参数进行相关分析。然后,采用独立样本t检验分析高/低拟人化AI组被试的拟人化感知、机器启发式、感知能力与温情以及C、N、I参数差异,在结果显著的基础上,加入控制变量,采用协方差分析验证结果的稳健性。最后,使用PROCESS4.1插件(Hayes, 2017)中模型4对感知温情的中介作用进行检验。
3.2 结果
3.2.1 操纵检验
独立样本t检验结果显示,高拟人化AI组(M=14.33, SD=3.38)和低拟人化AI组(M=6.73, SD=3.03)拟人化感知得分有显著差异[t(206)=−16.99, p<0.001, Cohen’s d=2.37]。说明对AI拟人化的操纵有效。
3.2.2 机器启发式、感知能力与温情、CNI参数相关分析
皮尔逊相关分析结果显示,机器启发式得分与感知能力(r=0.63, p<0.001),感知温情(r=0.22, p=0.002)显著正相关;C、N、I参数与机器启发式、感知能力、感知温情的相关系数均不显著;C参数与I参数显著正相关(r=0.15, p=0.034),与N参数显著负相关(r=−0.23, p=0.001),见表3 。
表3 各变量间相关分析结果 |
| 指标 | M(SD) | 1 | 2 | 3 | 4 | 5 |
| 1.机器启发式 | 34.37(3.82) | |||||
| 2.感知能力 | 18.26(1.78) | 0.63*** | ||||
| 3.感知温情 | 14.64(1.89) | 0.22** | 0.05 | |||
| 4.C参数 | 0.32(0.19) | 0.03 | −0.12 | 0.01 | ||
| 5.N参数 | 0.27(0.29) | −0.13 | 0.02 | 0.04 | −0.23** | |
| 6.I参数 | 0.49(0.19) | −0.05 | −0.08 | 0.01 | 0.15* | 0.09 |
3.2.3 机器启发式、感知能力与温情、CNI参数差异
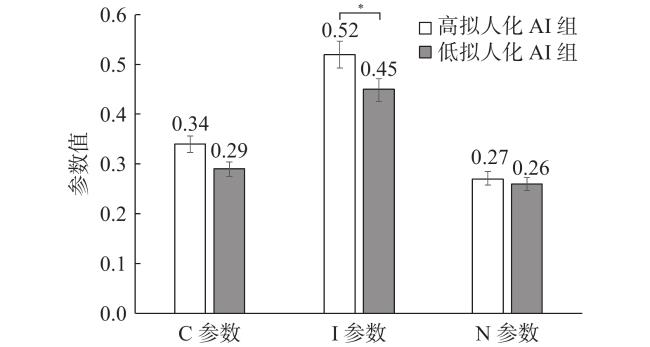
独立样本t检验结果显示,高拟人化AI组和低拟人化AI组被试在机器启发式量表得分[t(206)=0.29, p=0.775]与感知能力得分[t(206)=−0.88, p=0.381]上无显著差异,且均显著高于理论均值[M启发式理论均值=24, t(207)=39.16, p<0.001; M感知能力理论均值=12, t(207)=50.66, p<0.001],在感知温情得分上,前者显著高于后者[t(206)=4.89, p<0.001, Cohen’s d=0.66]。
在C参数[t(206)=1.81, p=0.072]与N参数[t(206)=0.12, p=0.904]上,两组无显著差异。在I参数上,高拟人化AI组被试显著高于低拟人化AI组[t(206)=2.62, p=0.009, Cohen’s d=0.38],且前者的I参数与临界值0.5差异不显著[t(106)=1.16, p=0.253],后者的I参数显著低于临界值0.5[t(100)=−2.68, p=0.009],表明被试在判断高拟人化AI的道德选择时,没有明显的接受/拒绝偏好,而在判断低拟人化AI时,更偏好接受其道德选择。结果见表4 。
表4 高/低拟人化AI组变量间差异检验 |
| 变量 | 高拟人化AI组 (n=107) | 低拟人化AI组 (n=101) | t | p | Cohen’s d |
| 机器启发式 | 34.44±3.76 | 34.29±3.89 | 0.29 | 0.775 | 0.04 |
| 感知能力 | 18.16±1.78 | 18.38±1.79 | −0.88 | 0.381 | 0.12 |
| 感知温情 | 15.86±3.09 | 13.36±4.23 | 4.89 | <0.001 | 0.66 |
| C参数 | 0.34±0.20 | 0.29±0.18 | 1.81 | 0.072 | 0.26 |
| N参数 | 0.27±0.29 | 0.26±0.28 | 0.12 | 0.904 | 0.04 |
| I参数 | 0.52±0.20 | 0.45±0.17 | 2.62 | 0.009 | 0.38 |
为检验结果的稳健性,以组别为自变量,性别(男=1, 女=2)、年龄、学历、对AI的熟悉、了解和喜爱程度、感知能力与感知温情为协变量进行协方差分析,结果显示,在I参数上,组别主效应依然显著[F(1, 198)=6.73, p=0.011, η$ _{\mathrm{p}}^{2} $ =0.03],在C参数[F(1, 198)=2.30, p=0.132]、N参数[F(1, 198)=0.01, p=0.985]上,组别主效应均不显著,结果不支持假设2。如图4 所示。
3.2.4 感知温情的中介作用
使用PROCESS4.1插件(Hayes, 2017)中模型4,将性别(男=1, 女=2)、年龄、学历、对AI的熟悉、了解和喜爱程度、感知能力作为控制变量,设定Bootstrap样本量为5000,采用偏差校正法,选取95%置信区间检验感知温情的中介作用。结果显示,感知温情在AI拟人化与C、I参数之间的中介作用不显著,在AI拟人化与N参数间中介效应值为0.07,95%CI=[0.006, 0.155],不包含0,表明中介作用显著。假设3成立。结果见表5 。
表5 感知温情的中介效应检验 |
| 路径 | 中介效应值 | 95%CI |
| AI拟人化→感知温情→C参数 | −0.03 | [−0.099, 0.052] |
| AI拟人化→感知温情→N参数 | 0.07 | [0.006, 0.155] |
| AI拟人化→感知温情→I参数 | −0.01 | [−0.075, 0.080] |
3.2.5 补充分析
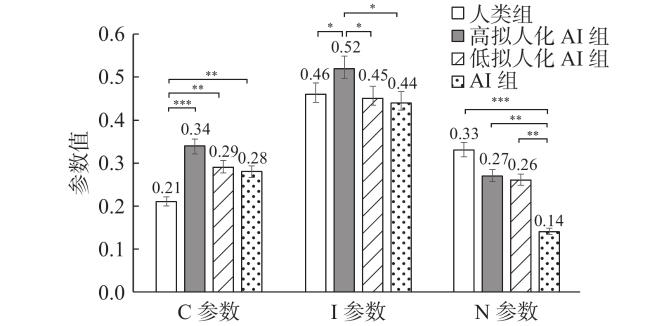
为比较当前研究与以往使用经典道德困境研究的结果一致程度,在现有数据中,将道德规范禁止但行为利益大于成本的情境中被试的接受频次视为对功利性选择的偏好,不接受频次视为对道义性选择的偏好,对实验1b和研究2中被试的数据进行分析。独立样本t检验结果显示,实验1b中被试接受AI选择的频次(M=7.59)显著高于接受人类[M=6.55, t(148)=2.59, p=0.011]。研究2中被试接受高拟人化AI选择的频次(M=7.15)与接受低拟人化AI选择的频次(M=7.06)没有显著差异[t(206)=0.27, p=0.785]。将实验1b与研究2的CNI参数进行联合分析,控制变量同实验1b,结果显示,C参数[F(3, 348)=7.30, p<0.001, η$_{\mathrm{p}}^{2} $ =0.06]、N参数[F(3, 348)=5.98, p=0.001, η$_{\mathrm{p}}^{2} $ =0.05]、I参数[F(3, 348)=3.58, p=0.014, η$_{\mathrm{p}}^{2} $ =0.03]差异均显著。事后比较显示,在C参数上,高拟人化AI组高于AI组,差异边缘显著(p=0.072),其余比较如图5 所示。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 讨论
本研究使用CNI模型探讨了人对人类与AI、高/低拟人化AI道德选择的判断差异,并检验感知温情在AI拟人化与这种差异之间的中介作用,对解释人关于人类与AI的道德判断不对称性具有积极意义。
相比于人类,人们在判断AI的道德选择时对道德规范更不敏感,对结果收益更敏感,此时的AI可能被当作一种算法。实验1a表明,判断AI的被试的N参数显著低于判断人类的被试,前者的C参数大于后者,但不显著。实验1b发现,相比于人类,被试在判断AI的选择时N参数更小,C参数更大,差异均显著。实验1b的结果可能更为合理。一方面,实验1b对个体的差异进行了控制,实验1a使用Gawronski等人(2017)编制的道德困境材料,不能估计个体水平的参数(云祥, 2020),对参数进行差异检验时无法排除个体差异,实验1b使用Körner等人(2020)改进的道德困境材料克服了这种局限。另一方面,实验1b的结果得到了以往研究的支持,研究发现人们不会以人类道德规范来评价AI的不道德行为,无论是在真实案例中(Wilson et al., 2022),还是在实验室条件下(许丽颖 等, 2022; Bigman et al., 2023),同时,人们认为AI比人类更加客观、理性,更应该优先考虑收益(Komatsu et al., 2021)。
拟人化提高了人们对AI的感知温情,进而促使人们将AI当作社会参与者,对其决策是否遵守道德规范更敏感。虽然研究2中AI拟人化对N参数影响不显著,但感知温情在AI拟人化和N参数之间确实发挥了中介作用。N参数代表对道德规范的敏感性,以往研究发现,赋予AI与人类相等的专业地位和能力时,人们对AI的道德建议态度与人类一致(Liu & Wang, 2025),研究2实验材料对AI性能的介绍可能造成了被试对高/低拟人化AI的感知能力都显著高于平均水平,导致被试将二者均作为社会参与者,因此AI拟人化对N参数影响不显著。将感知能力作为控制变量后,发现感知温情在AI拟人化与N参数之间具有中介效应,这对Zhang等人(2022)的研究结果做出了进一步解释:感知温情负向预测人们对AI功利性决策的概率估计,是因为感知温情提高了人们对AI遵守道德规范的预期。研究2发现感知温情的中介作用较小。N参数与社会角色(Gawronski & Brannon, 2020)等社会认知变量相关,感知温情虽然是社会认知的重要维度,但是当被试对AI的感知能力较高时,感知能力已经促使被试将AI作为社会参与者,如此一来,即使拟人化引起了感知温情的显著变化,该变化对N参数的影响也很微弱,造成中介效应较小。
在拟人化较强的情境下,AI的算法身份和引起的社会认知会共同影响道德判断。补充分析显示,AI拟人化同时提高了N参数与C参数,表明被试在判断高拟人化AI的道德选择时,既关注结果收益也关注道德规范。从C参数上看,相比于人类,被试在判断AI道德选择时对结果收益更敏感,而AI拟人化进一步提升了这种敏感性;从I参数上看,不同于其他三组被试习惯性接受人和AI的道德选择,高拟人化AI组被试没有明显的偏好,这可能由于该组被试同时关注AI的算法身份与引起的社会认知,令其既关注结果收益也关注道德规范,从而削弱了自身的习惯性倾向。
本研究的意义在于,一方面再次验证了CNI模型的合理性,证明功利性倾向与道义性倾向并非如经典道德两难预设的此消彼长,另一方面指出了促进AI向人类社会融入的策略:将AI的性能以拟人化的方式进行展示,将会同时提高人们对AI的能力与温情的感知,从而促进对AI的社会认知,更为重要的是,减弱人们对AI的算法本质的关注,从而避免将工具理性作为对AI的道德要求。
本研究存在一定的局限。第一,Körner等人(2020)编制的道德困境材料文字较多,导致有些被试未通过注意力检测,未来研究可以考虑将上述的道德困境材料进行改编,使其更加灵活、方便。第二,本研究中感知温情在AI拟人化与N参数之间的中介效应较小,未来研究可以考虑构造反映社会认知的潜在因子,关注其在AI拟人化与N参数之间的中介作用。
5 结论
(1)相较于人类,个体判断AI的道德选择时对结果收益更敏感,对道德规范更不敏感。(2)AI拟人化通过提升个体对AI的感知温情,增强其在判断AI道德选择时对道德规范的关注。