
1 引言
计算机自适应测验(computerized adaptive testing, CAT)能在测试过程中根据受测者的作答行为匹配最适合其作答的项目,从而提高测试效率和得分有效性(Fliege et al., 2005)。相较于基于经典测量理论(classical test theory, CTT)的传统测验,CAT一方面使受测者不再需要作答完量表的所有项目,在提高测量效率的同时减少了其认知负担;另一方面通过“因材施测”减少了因项目难度与受测者特质水平相差过大造成的测量误差。同时CAT以项目反应理论(item response theory, IRT)为基础,只要所有项目的参数标定在同一尺度上,那么即使作答的项目数量和难度不同,也能确保每位受测者的结果是可比的。因此,由存在共同测量目标且参数处于同一尺度上的项目组成的大型题库是CAT的基本前提,这既要求开发者收集大量项目并通过施测获得稳定的项目参数,以此构建最初的题库,又需要后续定期管理和补充题库。传统的项目开发往往依赖于领域专家,需要大量人力、物力与财力投入,因此题库构建是目前制约CAT发展与运用的一大瓶颈(Gierl & Haladyna, 2013)。
为解决这一难题,自动项目生成(automatic item generation, AIG)与CAT的结合被认为有广阔的前景(Hommel et al., 2022)。传统的AIG需要专家创建模板,再通过自动替换其中特定部分来生成新项目,目前已在教育测量中被广泛使用(Gierl & Haladyna, 2013)。但这种基于模板的AIG并不太适用于非认知测验,因为这类项目往往有更复杂的语义、情境和细微的差别(Hernandez & Nie, 2023; Hommel et al., 2022; Lee et al., 2023),导致采用同义词或近义词替换后产生的新项目作用十分有限。所幸的是,随着自然语言处理(natural language processing, NLP)的发展,逐渐有研究者尝试运用算法来自动生成非认知的测验项目(Götz et al., 2024; Hernandez & Nie, 2023; Hommel et al., 2022; Lee et al., 2023; von Davier, 2018)。
NLP是人工智能(artificial intelligence, AI)里通过开发量化模型来理解、分析和生成人类语言的子领域(Goldberg, 2017; Lee et al., 2023)。随着神经网络(一种模拟生物神经网络的计算模型,能将输入的数据在网络中根据给定的映射进行连续的转化后再输出; Goldberg, 2017)的引入,NLP取得了巨大的进展(Götz et al., 2024)。von Davier(2018)便开创性地将基于当时最先进的长短期记忆(long short-term memory, LSTM)网络的语言模型应用于非认知项目的AIG,但该技术无法根据特定目标概念生成项目,并存在计算量极大、难以保持项目语法正确性等局限(Hernandez & Nie, 2023; Hommel et al., 2022)。OpenAI发布的基于Transformer架构的生成式预训练模型(generative pre-trained transformer, GPT)及其迭代版本展现出了优越性能,受到了当前AIG领域研究者的青睐。
自注意力机制是Transformer一大特点,其能将一个输入序列中的任意单词与序列中其他单词进行交互,从而使每个单词的输出包含了与其他单词间关系的信息,这让模型能通过数学计算把握单词间的微妙联系,通过关键的上下文信息来预测内容(Vaswani et al., 2017)。GPT正是基于Transformer的解码器开发而来,这一形式已被证明更适合文本生成领域(Hommel et al., 2022)。用户只需几个例子就能让GPT-3执行特定任务,而不再需要大量人工标注的训练数据或针对特定任务对模型进行微调。后续OpenAI发布的基于GPT-3.5及GPT-4的ChatGPT,因其仅依靠对话而无需任何代码的使用形式,受到了广泛的关注。尽管更多技术细节没有公布,但GPT-4在各项任务中取得的优异成绩及对比先前版本取得的显著进步,使其生成非认知项目的表现令人期待。此外,GPT-4同样有优秀的理解与生成中文的能力,验证GPT能否在中文语境下生成质量良好的项目同样必要。
鉴于经典CAT需满足单一维度的测量目标,在参考前人范式的基础上,本研究仅选择大五人格的情绪稳定性维度作为生成目标。在理论层面,数个经典大五量表中的情绪稳定性项目在跨国家样本中均展现出了较其他维度最高的信度及质量(王孟成 等, 2011; DeYoung et al., 2007; Zhang et al., 2022),选择该维度的经典项目进行对比更能说明GPT生成项目的质量;而在现实意义上,情绪稳定性被认为是人格中最重要的领域之一,其有重要的公共卫生意义,广泛影响着身体健康与生活质量的多个方面(Widiger & Oltmanns, 2017)。因此,本研究旨在基于ChatGPT生成中文版的情绪稳定性项目,初步探索使用这些人格项目构建题库以进行CAT的可能性并检验其性能,验证将基于ChatGPT的AIG用于构建CAT题库的可行性。
2 研究方法
2.1 测量工具
为生成符合要求的项目,本研究对ChatGPT进行了一系列提示工程,主要包括:要求ChatGPT扮演经验丰富的心理学家;介绍相关概念的定义;描述任务;规定基本原则;逐次提供示例题目并要求开始生成项目(提示语与生成的项目附于:https://osf.io/u238p/?view_only=c89950af7efa4a499cdf1b9e94a3c3aa)。考虑到中文语境下,神经质可能导致歧义或偏见,因此本研究选择了情绪稳定性的概念,尽管如此,提示语中限定了情绪稳定性是与神经质处于一个量尺上两端的关系,且示例项目均来自经典大五量表的神经质维度。因此本研究后续涉及的所有项目,得分越高代表神经质水平越低。
本研究共得到GPT制定的114道项目,并邀请了10位经培训的心理学专业的研究生评定者对项目语法与内容有效性进行判断。其中1道表述不当的项目被剔除,接着10位评定者对每个项目代表情绪稳定性的程度进行4点评分。根据结果,计算了修正后的kappa系数(k*; Polit et al., 2007)。按照Polit等人的标准,k*大于0.74的属于优质项目,因此所有不符合该标准的项目被剔除,最终75道项目得以保留。
另外还选择了4个已被广泛使用的大五人格量表中共计42道神经质的项目进行施测。包括中国大五人格问卷简式版(CBF-PI-B; 王孟成 等, 2011),大五人格问卷第二版(BFI-2; Zhang et al., 2022),翻译后的十项目大五人格量表(Ten-Item Personality Inventory, TIPI-10; Gosling et al., 2003)及大五人格方面量表(The Big Five Aspect Scales, BFAS; DeYoung et al., 2007)。本研究中,这四个量表的神经质维度的Cronbach’s α分别为0.921、0.935、0.799、0.955。
在计算效标关联效度时,本研究将BFI-2和中国大五人格问卷极简版(CBF-PI-15; Zhang et al., 2019)作为与GPT生成项目进行对比的参考,选择主观幸福感量表(Diener et al., 1985)和抑郁量表(Norton, 2007)作为效标。
2.2 被试
本研究包含4个利用问卷星进行方便抽样获得的样本数据。主要的样本1是对保留的75道GPT生成的项目以及42道经典项目进行施测得到的,包括有效数据479人(男163人),平均年龄22.82±6.52岁,其用于题库构建、质量分析以及模拟CAT。另外,分别单独施测了CBF-PI-B与BFI-2的神经质项目来计算测验信度,用以与样本1的结果进行跨样本的信度比较,获得的有效样本分别记为样本2与样本3。样本2共2484人(男820人),样本3共655人(男197人)。样本4则是对GPT题库的项目、BFI-2、CBF-PI-15以及主观幸福感和抑郁的项目进行施测获得,用于效标关联效度的计算,共262人(男125人),平均年龄22.39±4.13岁。所有被试都已知情同意,本研究经天津师范大学伦理委员会批准(2023080902)。
2.3 分析方法
为方便表述,将经典量表的项目记为经典题库,GPT生成的项目记为GPT题库,并分别对这两个题库在样本1上的数据按以下步骤进行分析,以对题库质量进行检验与比较,剔除不合要求的项目:(1)为删除与测量目标相关性低的项目,首先对题库进行主成分分析(principal component analysis, PCA),又由于单维性是IRT的前提假设之一(Hambleton et al., 1991),需要对剩余项目进行单维性检验。(2)根据模型拟合指标,进行IRT模型选择,以便获得更准确的项目参数。(3)通过项目分析剔除问题项目,主要为存在项目功能差异(differential item functioning, DIF)的项目,DIF指不同群体的受测者在匹配项目欲测量的潜在特质后,仍在该项目上表现出了不同的统计特性,即项目出现了与测量目标无关但会对结果造成系统性影响的因素。这会干扰对被试特质水平的估计,影响测验的公平性,尤其在CAT形式中每位被试作答的项目更少的情况下,如果作答项目中存在DIF较传统测验会产生更显著的影响(Wainer et al., 2000)。当前NLP模型重要基础之一的词嵌入表现出了一致的性别偏见(Lee et al., 2023),而这会导致项目存在性别的DIF。词嵌入指将每个单词表示成一定维度向量的技术,不同词之间的关系通过词向量的差异来捕获(Bolukbasi et al., 2016),现实中的刻板印象会导致词嵌入技术错误地捕获了这些关系(Garg et al., 2018),从而导致输出文本中可能存在偏见。因此为避免项目文本中的偏见对测量结果造成的系统差异,需要进行性别的项目功能差异检验。另外,区分度也是评估项目质量的重要指标。(4)计算题库信息量与边际信度以评估题库整体质量。
将前两个题库最终保留的项目汇总形成第三个题库(记为总题库),并用样本1数据按上述步骤再次对其进行检验,验证两种来源项目的可结合性,以期获得一个更丰富的终版题库。之后,根据样本1在全部项目上的真实作答情况分别进行基于三个题库的模拟CAT,通过计算三个题库CAT在不同精度下的测量误差、边际信度以及与能力真值的相关系数等指标,对比GPT项目与经典项目的性能优劣;另一方面,通过比较同精度下CAT与经典测验形式所用题目数,比较同题目数下CAT与经典测验形式的测验误差,以及根据更大的样本2/样本3在CBF-PI-B与BFI-2上的作答结果进行跨样本信度比较等步骤,验证CAT相较于传统测验的性能提升。最后为了证实构建题库的有效性,使用样本1数据计算了三个题库的收敛效度,并使用样本4额外针对GPT题库进行了效标关联效度的计算。
各步骤详情如下。
2.3.1 主成分分析与单维性检验
为保证题库质量,删除PCA结果中在第一主成分载荷小于0.4的项目。
已有研究表明,在探索性因素分析(exploratory factor analysis, EFA)中,第一特征值与第二特征值比值大于4且第一因子解释方差大于20%,则可以视为满足单维性假设(Liu et al., 2022; Reckase, 1979; Reeve et al., 2007)。
2.3.2 IRT模型选择
因本研究的项目均为多级计分,可选的IRT模型主要有拓广分部评分模型(generalized partial credit model, GPCM; Muraki, 1992)与等级反应模型(graded response model, GRM; Samejima, 1969)。本研究将比较两个模型的拟合指数,主要是AIC(Akaike, 1974)与BIC(Schwarz, 1978),以选择拟合更优的模型进行后续的参数估计。
2.3.3 项目分析
本研究采用逻辑回归的方法来检验是否存在性别引起的DIF,当McFadden’s pseudo R2大于0.02时,表明该项目存在DIF,需要考虑删除(Choi et al., 2011)。
区分度指项目对不同能力水平的被试的鉴别力,其数值较低表示项目难以区分不同能力水平的被试。一般认为区分度大于0.8的项目是可接受的(Liu et al., 2022),低于该标准的项目需要删除。
2.3.4 题库信息量与边际信度
项目信息量代表项目在评价被试特质水平时提供信息的确定性水平,其值越大,表明项目的可靠性越高。测验信息量是所有测验项目信息量之和。整个测验整体的可靠性用边际信度(marginal reliability, MR)来表示(Liu et al., 2022; Xu et al., 2020),相关计算公式见公式1。
其中θj代表被试j的潜在特质水平,m为测验的项目总数,Ii(θj)表明第i个项目对于特质水平为θj的被试提供的信息量,SE(θj)代表该被试作答完测验后的能力估计值的标准误。
测验的边际信度可借助所有受测者的平均测量标准误计算得到。见公式2、公式3。
其中N代表被试总人数,j代表第j个被试,$ {S} {E}\left({\mathrm{\theta }}_{\mathrm{j}}\right) $ 代表第j个被试在最终θ估计值时的测量标准误。
2.3.5 模拟CAT
模拟CAT选题采用最大信息量法,能力估计采用期望后验估计法,将答完全部117道题时的能力估计值视为真值。在终止规则方面,首先采用固定测量精度的规则,即当能力估计的标准误达到特定值时停止测验(本研究采用MR=0.80/0.85/0.90/0.95对应的SE=0.447/0.387/0.316/0.224,以及四个已有量表实际测量后得到的SE= 0.34/0.27/0.46/0.21);接着,采用定长的终止规则,即作答的题数达到规定值后停止测验(长度对应四个经典量表中项目的数量为12/8/20/2),同时估计被试以传统测验形式作答4个经典量表项目时的能力值与测量误差。提供在上述各种条件下从GPT题库随机抽取42个项目100次的平均结果作为额外参考。并根据样本2、样本3在传统测验上的结果进行信度比较。
2.3.6 效度
收敛效度计算以四个经典量表的神经质维度为基准,分别计算样本1被试在三个题库中作答所有项目后的能力估计值与这4个量表上得分的相关系数,以此来验证三个题库的效度。
回顾前人研究发现,大五人格中的情绪稳定性是主观幸福感最可靠的预测因素之一(Womick & King, 2020),也是抑郁风险最有效的预测指标(Kendler et al., 2002),同时这两个指标也是大五人格量表开发常用的效标(Zhang et al., 2022),因此为进一步证实GPT题库的有效性,本研究根据样本4在GPT题库、CBF-PI-15和BFI-2神经质维度以及上述两个效标的作答,在积极与消极表现两个方面计算了效标效度,并进行了比较。
2.4 研究工具
本研究采用基于OpenAI于2023年11月初发布的GPT-4 Turbo版本的ChatGPT进行项目生成,采用SPSS26.0进行PCA和单维性检验,其余分析则采用R软件包,主要包括mirt1.41、lordif0.3-3和catR3.17。
3 结果
3.1 题库构建
3.1.1 单维性检验
分别对经典题库和GPT题库的项目进行PCA,结果表明所有项目在第一主成分上的载荷均大于0.4(详情见图1 )。
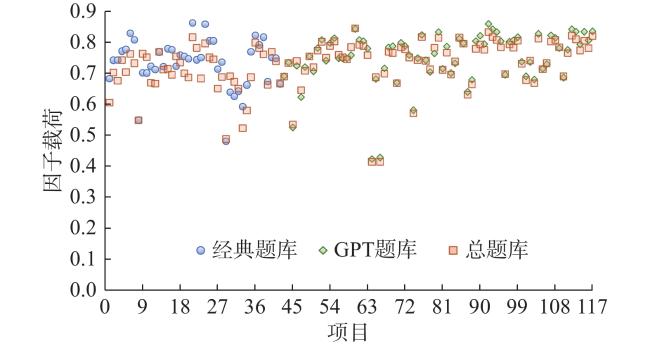
接着对这两个题库分别进行了KMO测试,结果为0.979、0.986,证实了数据进行因子分析的适用性。EFA结果显示经典题库的第一、第二特征值分别为22.75、2.29,比值为9.92,且第一因子解释方差达到53.28%,GPT题库的第一、第二特征值分别为42.93、1.97,比值为21.78,第一因子解释方差达到56.79%,表明这两个题库均满足单维性假设(Liu et al., 2022)。
3.1.2 IRT模型选择
结果如表1 所示,这两个题库在GRM拟合中的AIC与BIC均更小,因此GRM被用于后续的分析。
表1 模型拟合指标值 |
| 模型 | AIC | BIC | Loglik |
| 经典题库 | |||
| GRM | 47240.97 | 48167.08 | −23398.48 |
| GPCM | 47820.24 | 48746.35 | −23688.12 |
| GPT题库 | |||
| GRM | 74640.70 | 76242.64 | −36936.35 |
| GPCM | 75556.12 | 77158.05 | −37394.06 |
| 总题库 | |||
| GRM | 122730.8 | 125258.8 | −60759.38 |
| GPCM | 124201.5 | 126729.6 | −61494.76 |
3.1.3 项目分析
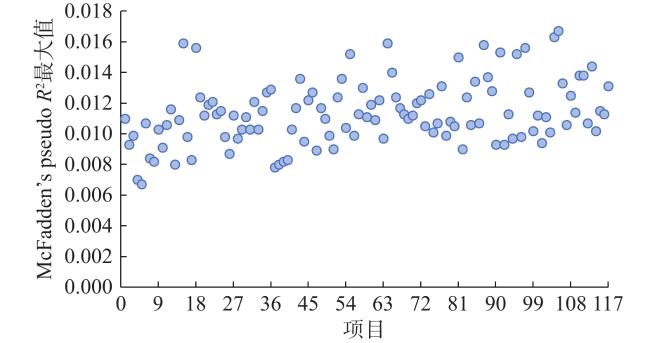
性别的DIF结果显示,所有项目McFadden’s pseudo R2值均小于0.02(详见图2 ),表明不存在性别引起的系统误差。
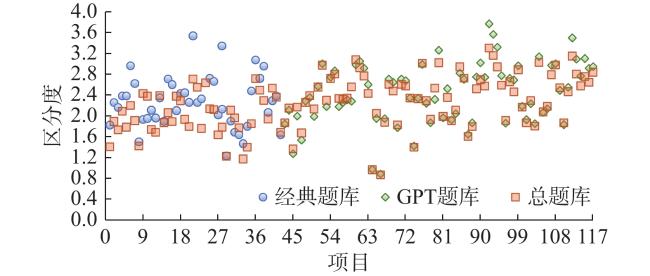
参数估计结果显示,所有项目区分度均大于0.8(图3 )。
3.1.4 题库信息量与边际信度
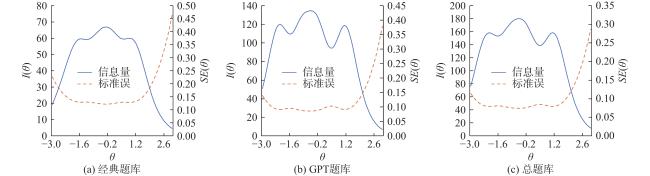
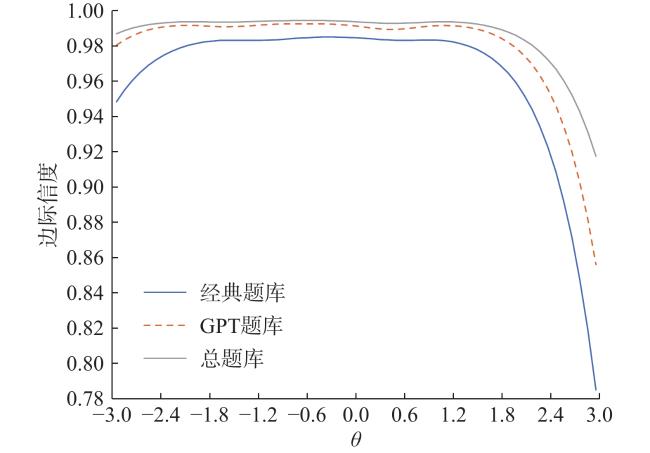
经典题库和GPT题库的测验信息量及标准误见图4a 、图4b ,一般值不高于0.39被视为低标准误(Xu et al., 2020)。总的来说这两个题库均能为大部分被试提供较高的信息量及较低的测量误差。此外,两个题库的边际信度如图5 所示,其平均值分别高达0.96、0.98。相较而言,GPT题库整体质量较经典题库更高。
3.1.5 总题库构建
最终保留的117道题组成总题库。对总题库进行PCA,得到所有项目在第一主成分载荷均大于0.4(见图1 )。KMO结果为0.986, EFA结果显示第一、第二特征值分别为62.98、4.47,比值为14.10,第一因子解释方差达到53.83%,满足单维性假设。
拟合指标同样表明GRM更优(见表1 ),参数估计结果表明所有项目区分度仍均高于0.8(图3 )。
最后对总题库的信息量、测量标准误以及边际信度进行计算(见图4c 、图5 ),总体上看总题库相较前两个题库有更小的测量误差与更高的可靠性。
3.2 模拟CAT
3.2.1 定测验精度下三个题库模拟CAT的表现
表2 不同精度停止条件下的模拟结果 |
| 题库 | 终止规则 | M题数 | SD题数 | MSE(θ) | MMR | r真值 |
| 经典题库 | 全部 | 42 | 0.15 | 0.98 | 0.986*** | |
| SE(θ)≤0.447 | 2.60 | 0.88 | 0.41 | 0.83 | 0.900*** | |
| SE(θ)≤0.387 | 3.77 | 1.73 | 0.36 | 0.87 | 0.929*** | |
| SE(θ)≤0.316 | 5.87 | 3.23 | 0.30 | 0.91 | 0.950*** | |
| SE(θ)≤0.224 | 12.90 | 4.77 | 0.22 | 0.95 | 0.978*** | |
| GPT题库 | 全部 | 75 | 0.09 | 0.99 | 0.992*** | |
| SE(θ)≤0.447 | 2.40 | 1.06 | 0.40 | 0.84 | 0.921*** | |
| SE(θ)≤0.387 | 3.06 | 1.18 | 0.36 | 0.87 | 0.930*** | |
| SE(θ)≤0.316 | 4.90 | 3.76 | 0.30 | 0.91 | 0.953*** | |
| SE(θ)≤0.224 | 10.11 | 6.94 | 0.22 | 0.95 | 0.976*** | |
| GPT 题库(42) | 全部 | 42 | 0.13 | 0.98 | 0.996*** | |
| SE(θ)≤0.447 | 2.48 | 0.86 | 0.40 | 0.84 | 0.994*** | |
| SE(θ)≤0.387 | 3.35 | 1.75 | 0.36 | 0.87 | 0.995*** | |
| SE(θ)≤0.316 | 5.15 | 3.05 | 0.30 | 0.91 | 0.996*** | |
| SE(θ)≤0.224 | 10.51 | 4.12 | 0.22 | 0.95 | 0.996*** | |
| 总题库 | 全部 | 117 | 0.08 | 0.99 | ||
| SE(θ)≤0.447 | 2.42 | 0.96 | 0.39 | 0.84 | 0.916*** | |
| SE(θ)≤0.387 | 3.15 | 1.39 | 0.36 | 0.87 | 0.932*** | |
| SE(θ)≤0.316 | 4.79 | 3.30 | 0.30 | 0.91 | 0.948*** | |
| SE(θ)≤0.224 | 10.14 | 8.38 | 0.22 | 0.95 | 0.971*** |
注:r真值代表能力估计值与能力真值的相关系数,GPT题库(42)为从GPT题库随机抽取42个项目100次后的平均结果;***p<0.001,以下同。 |
表3 达到传统测验精度所需项目数 |
| SECBF-PI-B=0.34 | SEBFI-2=0.27 | SETIPI=0.46 | SEBFAS=0.21 | |
| 传统测验题数 | 8 | 12 | 2 | 20 |
| 经典题库题数 | 5.07 | 8.44 | 2.51 | 15.13 |
| GPT题库题数 | 4.18 | 6.86 | 2.27 | 11.63 |
| GPT题库(42)题数 | 4.42 | 7.12 | 2.37 | 11.97 |
| 总题库题数 | 4.20 | 7.08 | 2.27 | 11.52 |
相同精度下,GPT题库所需的题数均少于经典题库,且前者边际信度及与能力真值的相关系数也与后者的结果相似甚至略优。同时,达到传统测验精度的情况下,GPT题库所需项目数也少于经典题库。
3.2.2 定测验长度下三个题库模拟CAT的表现
表4 相同测验长度时不同方法的测量误差 |
| 来源 | 测验长度 | Mθ (SDθ) | 测量误差 | 边际信度 | |||||
| M(SD) | t | Cohen’s d | M(SD) | t | Cohen’s d | ||||
| CBF-PI-B | 8 | −0.08 (0.87) | 0.34 (0.03) | 0.88 (0.03) | |||||
| 经典题库 | 8 | −0.03 (0.98) | 0.27 (0.03) | 48.06*** | 2.20 | 0.93 (0.02) | 41.97*** | 1.92 | |
| GPT题库 | 8 | −0.06 (0.98) | 0.24 (0.03) | 72.67*** | 3.32 | 0.94 (0.02) | 61.99*** | 2.83 | |
| GPT题库(42) | 8 | −0.06 (0.95) | 0.24 (0.03) | 70.63*** | 3.23 | 0.94 (0.02) | 59.16*** | 2.70 | |
| 总题库 | 8 | −0.06 (0.99) | 0.23 (0.03) | 68.15*** | 3.11 | 0.94 (0.02) | 57.68*** | 2.64 | |
| BFI-2 | 12 | −0.06 (0.98) | 0.27 (0.02) | 0.93 (0.02) | |||||
| 经典题库 | 12 | −0.05 (0.99) | 0.23 (0.03) | 43.73*** | 2.00 | 0.95 (0.01) | 39.20*** | 1.79 | |
| GPT题库 | 12 | −0.06 (1.00) | 0.20 (0.03) | 65.97*** | 3.01 | 0.96 (0.02) | 57.61*** | 2.63 | |
| GPT题库(42) | 12 | −0.06 (0.97) | 0.20 (0.03) | 74.32*** | 3.40 | 0.96 (0.01) | 66.13*** | 3.02 | |
| 总题库 | 12 | −0.07 (0.98) | 0.19 (0.03) | 70.91*** | 3.24 | 0.96 (0.01) | 61.47*** | 2.81 | |
| TIPI | 2 | −0.08 (0.87) | 0.46 (0.05) | 0.79 (0.05) | |||||
| 经典题库 | 2 | −0.06 (0.92) | 0.46 (0.05) | –1.27 | –0.06 | 0.78 (0.05) | –1.29 | –0.06 | |
| GPT题库 | 2 | −0.03 (0.94) | 0.43 (0.05) | 10.78*** | 0.49 | 0.81 (0.05) | 9.87*** | 0.45 | |
| GPT题库(42) | 2 | −0.05 (0.82) | 0.43 (0.03) | 10.41*** | 0.48 | 0.81 (0.03) | 10.19*** | 0.47 | |
| 总题库 | 2 | −0.08 (0.89) | 0.42 (0.05) | 13.43*** | 0.61 | 0.82 (0.05) | 12.34*** | 0.56 | |
| BFAS | 20 | −0.05 (1.00) | 0.21 (0.03) | 0.95 (0.02) | |||||
| 经典题库 | 20 | −0.06 (0.99) | 0.19 (0.02) | 41.10*** | 1.88 | 0.97 (0.01) | 29.91*** | 1.37 | |
| GPT题库 | 20 | −0.06 (1.01) | 0.16 (0.03) | 72.31*** | 3.30 | 0.97 (0.01) | 51.91*** | 2.37 | |
| GPT题库(42) | 20 | −0.06 (0.99) | 0.17 (0.03) | 77.45*** | 3.54 | 0.97 (0.01) | 52.34*** | 2.39 | |
| 总题库 | 20 | −0.06 (1.01) | 0.16 (0.02) | 78.38*** | 3.58 | 0.97 (0.01) | 48.12*** | 2.20 | |
表5 跨样本下相同测验长度的测量信度 |
| 来源 | 测验长度 | 边际信度 | |||
| M(SD) | MR增加百分比(%) | t | Cohen’s d | ||
| 样本2 CBF-PI-B | 8 | 0.88 (0.03) | |||
| 经典题库 | 8 | 0.93 (0.02) | 5.39 | 37.48*** | 1.87 |
| GPT题库 | 8 | 0.94 (0.02) | 7.12 | 50.83*** | 2.54 |
| 总题库 | 8 | 0.94 (0.02) | 7.13 | 50.66*** | 2.53 |
| 样本3 BFI-2 | 12 | 0.93 (0.01) | |||
| 经典题库 | 12 | 0.95 (0.01) | 1.77 | 20.16*** | 1.21 |
| GPT题库 | 12 | 0.96 (0.02) | 2.98 | 31.23*** | 1.88 |
| 总题库 | 12 | 0.96 (0.01) | 3.13 | 36.58*** | 2.20 |
此外,GPT题库相较于经典题库,在同样的测验长度下,显著降低了测量误差[8题: t(478)=26.38, p<0.001; 12题: t(478)=30.35, p<0.001; 2题: t(478)=12.07, p<0.001; 20题: t(478)=37.13, p<0.001],并显著提高了测量信度[8题: t(478)=22.53, p<0.001; 12题: t(478)=24.68, p<0.001; 2题: t(478)=11.13, p<0.001; 20题: t(478)=29.28, p<0.001]。
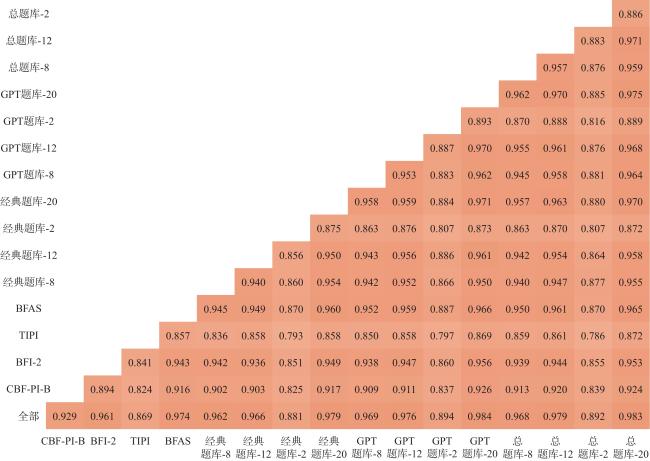
最后比较了相同测验长度下,不同方法下能力估计值间以及与能力真值间的相关系数,并通过热力图来直观展示CAT测量的准确性与稳定性。从图6 可以看出,GPT题库得到的能力估计值与能力真值的相关系数普遍高于经典题库。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3.2.3 效度验证
收敛效度如表6 所示,从中不难发现三个题库均与四个经典量表存在显著的相关(p<0.001),说明三个题库具有理想的效度。基于样本4的效标效度结果如表7 所示,GPT题库也表现出了令人满意的效标效度。
表6 三个题库与经典量表的收敛效度 |
| 题库 | CBF-PI-B | BFI-2 | TIPI | BFAS |
| 经典题库 | 0.832*** [0.804, 0.858] | 0.913*** [0.896, 0.929] | 0.860*** [0.831, 0.885] | 0.914*** [0.893, 0.930] |
| GPT题库 | 0.831*** [0.800, 0.857] | 0.917*** [0.900, 0.933] | 0.861*** [0.834, 0.886] | 0.918*** [0.898, 0.934] |
| 总题库 | 0.836*** [0.807, 0.862] | 0.921*** [0.906, 0.935] | 0.862*** [0.835, 0.885] | 0.919*** [0.899, 0.935] |
注:括号内的值代表基于1000次Bootstrap抽样的95%置信区间,以下同。 |
表7 效标效度 |
| 题目来源 | 主观幸福感 | 抑郁 |
| GPT题库 | 0.711*** [0.646, 0.774] | −0.647*** [−0.732, −0.552] |
| CBF-PI-15 | 0.533*** [0.438, 0.608] | −0.646*** [−0.710, −0.573] |
| BFI-2 | 0.658*** [0.573, 0.728] | −0.716*** [−0.780, −0.648] |
4 讨论
结果表明,GPT题库有良好质量,并展现出较经典题库更优异的CAT性能。总题库则在有足够效度的同时,相较于传统测验在测量精度与效率方面都有较大的提升。
本研究创新性地运用ChatGPT构建中文版人格自适应题库。该方法为构建题库提供了一种高效且经济的途径。同时ChatGPT这一对话的使用形式,相较于前人所使用的旧版本(Götz et al., 2024; Hernandez & Nie, 2023; Lee et al., 2023),不再要求研究者拥有扎实的NLP与机器学习基础来微调模型,甚至不再需要进行编程,极大降低了项目开发者的上手门槛。
通过本研究的探索可以发现GPT在生成非认知项目方面有巨大潜力,AIG逐渐展现出的对于人工项目编制的替代性,也提示着心理学人的职责转变。后续研究者应更关注对测量目标进行准确详细的定义,正如前人所说“项目生成和概念表征是相辅相成的”(Gierl & Haladyna, 2013)。同时,不仅项目质量仍需要专家制定评判标准并审核,标准化项目生成的流程,制定全面且完善的项目生成原则等也都是后续研究者需要努力的方向。
通过探讨GPT题目在部分方面展现出较传统题目优势的原因也有助于深化如何开发优质项目的认识。一方面,本研究用于对比的经典量表(如BFI-2/TIPI/BFAS)多数为英文量表的中文修订或翻译,而GPT在训练中接触了大量中文数据,通过中文问答生成的项目可能更适合中文测试者;另一方面,即使是经验丰富的专家也难免在思维上存在局限性,尤其是短时间内有大量题目开发的需求时,而在大规模数据训练的基础上,GPT或许能为测验目标联想到更丰富的测试情境,并采用更灵活多样的语言表达方式。
尽管本研究为基于最新NLP技术的AIG与CAT结合提供了有力证据,但仍然存在一些局限之处:一方面,GPT生成的项目仍存在局限,例如缺乏反向计分的项目;另一方面,CAT的相关算法是否有更优的选择也有待商榷。
总体而言,NLP的发展为非认知项目的AIG及以此为基础的CAT提供了易上手且表现良好的工具。本研究利用基于GPT-4 Turbo的ChatGPT,展示了大语言模型在自适应题库生成中的巨大潜力,提出了一种符合AI发展趋势下的大型题库开发的补充方案。在未来的研究中,GPT能否应用于更广泛测量目标的项目生成,需要进一步探索,同时迫选题等更丰富的测验形式能否借助于新技术得到进一步的发展也令人期待。
5 结论
基于ChatGPT的自动项目生成技术能够低成本高效生成质量良好的中文情绪稳定性人格项目,并能用于构建性能优异的自适应测验题库。