
1 引言
作为执行功能的核心元素之一,抑制控制(inhibitory control)是指个体调整注意力、思维和情感来主动抑制干扰信息,实现预定目标的能力(Diamond, 2013)。这一能力不仅是适应复杂环境的重要基础,还对推理、计划和学习等高级认知过程起关键作用(陈洁佳 等, 2020)。常见的测量任务包括Stroop、Flanker、Go/No-go和反向线索任务等。
语言和音乐作为人类社会中特有的两大系统,在加工过程中展现出显著的相似性(Patel, 2006)。例如,二者都依赖于层级结构处理,这需要听者抑制无关干扰,并将注意力集中于关键线索。此外,语言和音乐的加工高度依赖时间精准性,其中注意力分配和抑制控制发挥着重要作用(Ding et al., 2017)。已有研究分别探讨了双语和音乐经验对抑制控制能力的影响,但鲜有研究对比二者在抑制控制影响上的异同。双语经验通过频繁的语言切换增强了抑制能力,而音乐经验则可能通过复杂节奏的感知提升时间加工中的抑制能力(Bialystok & DePape, 2009)。此外,以往研究在探讨双语或音乐经验时,通常未能控制另一变量,可能导致结果混淆。因此,本研究将二语水平和音乐经验置于同一框架内,结合严格的分组设计和双语Stroop任务,探讨二者对抑制控制能力的影响。
“双语优势效应”指双语者在解决冲突任务中的表现优于单语者,这一效应已被多个研究验证(焦江丽 等, 2020; Bialystok et al., 2008)。例如,Bialystok等人通过Stroop和Simon任务发现,无论青年还是老年的双语者,其抑制控制能力均优于同龄单语者。此外,高姗等人(2017)采用Stroop范式探究了不同语言条件下双语优势效应。结果发现,在一语(维吾尔语)条件下,高水平的双语者能更快地克服语义干扰进行颜色辨认,而这种优势在二语(汉语)条件下则未显现。双语者抑制控制能力的增强可能源于日常交流中抑制非目标语言的激活以及频繁的语言切换,这种持续的行为有助于锻炼他们的抑制控制能力(Bialystok et al., 2008)。
然而,并非所有研究都支持双语者在抑制控制方面具有优势(李恒, 曹宇, 2016; 张高德, 陈飞, 2023)。例如,Kousaie和Phillips(2012)发现,尽管双语者在Stroop任务的一致和不一致条件下的反应时均短于单语者;但二者的Stroop效应并无显著差异。李恒和曹宇的研究也指出,尽管高水平英汉双语者展现出较强的语言抑制能力,但低水平双语者与英语单语者在同音异义词干扰任务中的表现无显著差异,这说明双语优势可能受到二语水平的影响。相比于单−双语者对比研究,关于双语者二语水平差异的研究较少,且结果不一致(蔡厚德, 2010; 高姗 等, 2017; 李恒, 曹宇, 2016; 张高德, 陈飞, 2023)。例如,蔡厚德通过中英Stroop测试发现,高水平双语者在一语和二语任务中的干扰效应均显著低于低水平者;而张高德和陈飞则发现高水平双语者在二语的语义−韵律不一致任务中受到更大的干扰,指出二语水平的提高并不必然增强处理干扰信息的能力。这些不一致结果可能源于三点:首先,部分研究仅通过语言等级来划分二语水平(蔡厚德, 2010; 高姗 等, 2017),未进行统一的语言量化评估,可能导致二语水平分类缺乏精准性。其次,现有研究大多未控制可能影响抑制控制的混淆变量(如音乐经验),增加了结果的不确定性。最后,任务设计差异也会影响结果的可比性。例如,张高德和陈飞聚焦听觉通道的语义−韵律冲突,探讨二语水平对二语加工的影响;而蔡厚德和本研究则关注视觉通道的语义−颜色冲突,同时考察二语水平对一语和二语任务的影响。综上,二语水平如何影响抑制控制,尤其在不同语言熟悉度条件下(一语vs.二语)的表现仍需进一步探讨。本研究采用标准化语言测试来量化二语水平,并控制音乐经验等混淆因素,为揭示二语水平在不同任务条件下对抑制控制的影响提供更全面的证据。
和双语优势相似,研究发现音乐经验也可提升抑制控制能力(张航 等, 2023; Bialystok & DePape, 2009)。例如,声乐歌唱家和器乐演奏家在听觉Stroop任务和视觉Simon任务中的反应时显著短于普通人(Bialystok & DePape, 2009)。类似地,王婷等人(2019)研究发现,侗歌组被试在视觉和听觉Stroop任务中的正确率和反应速度均优于非侗歌组。音乐经验带来的认知优势源于音乐家在演奏中需持续监控动作、调整反馈并抑制干扰,这一过程依赖于抑制控制(王婷 等, 2019)。另外长期音乐训练能通过增强神经连接和激活认知相关脑区进一步提升抑制控制能力(Fauvel et al., 2014)。
然而,也有研究发现音乐经验与抑制控制之间并无显著关系(Slevc et al., 2016; Zuk et al., 2014)。例如,Zuk等人发现,无论成人还是儿童,音乐训练组在Stroop色词任务中的表现均未优于控制组。Slevc等人的研究同样发现音乐训练并不能预测被试在Stroop和Simon任务的表现。导致这一争议的可能因素包括年龄、双语经验等未控制的变量。例如,王婷等人(2019)指出,无论侗族被试是否具有侗歌经验,其Stroop效应均显著低于汉族被试,这可能源于侗语和汉语的双语经验,而相关研究大多未对语言经验加以控制。因此,本研究将严格控制被试的年龄、语言经验、音乐训练时长等因素,以深入探究音乐经验对于抑制控制的影响。
综上所述,尽管二语水平和音乐经验对抑制控制的影响已被广泛研究,但结论尚不一致。为此,本研究采用中英双语Stroop范式探究二语水平和音乐经验对中国英语学习者在一语(汉语)和二语(英语)条件下抑制控制的影响。具体研究问题包括:(1)二语水平如何影响中国英语学习者在一语和二语Stroop任务中的抑制控制能力?(2)音乐经验如何影响中国英语学习者在一语和二语Stroop任务中的抑制控制能力?(3)二语水平和音乐经验对抑制控制的影响是否存在差异?
2 研究方法
2.1 被试
本研究招募了60名被试,均为长沙市在校大学生(男生10名,女生50名),年龄18~26岁。所有被试无言语和听力障碍,视力或矫正视力正常,母语为普通话,从小学开始接受义务教育英语课程,无方言背景。根据二语水平和音乐经验将被试分为三组:高水平二语组(20名)为通过英语专业八级考试且无课程外音乐训练的英语专业学生;高水平音乐组(20名)为未通过大学英语六级考试的音乐专业学生;低水平对照组(20名)为未通过大学英语六级考试且无课程外音乐训练的非英语、非音乐专业学生。
为精确评估二语水平和音乐能力,被试完成了LexTALE词汇测试(Lemhöfer & Broersma, 2012)和音乐耳测试(Musical Ear Test, MET)(Correia et al., 2022)。LexTALE测试评估被试对英语词汇的掌握情况及整体英语水平。MET测试包括节奏和旋律两部分,用于客观测量被试的音乐能力。被试的具体信息及测试得分见表1 。对LexTALE和MET测试得分进行方差分析,结果表明:高水平二语组在LexTALE测试中的得分显著高于其他两组(ps<0.001),而高水平音乐组的MET得分显著高于其余两组(ps<0.001),表明各组间的二语水平和音乐经验控制得当。被试在实验前签署知情同意书,并在实验结束后获取报酬。
表1 被试基本情况与二语水平、音乐能力测试得分 |
| 高水平二语组 | 高水平音乐组 | 低水平对照组 | |
| 被试数量(男性, 女性) | 20(3, 17) | 20(3, 17) | 20(4, 16) |
| 年龄(岁) | 23.90(0.72) | 22.15(1.90) | 20.20(2.14) |
| 专业类型 | 英语专业 | 音乐专业 | 非英语、 非音乐专业 |
| 惯用手(右, 左) | 20, 0 | 20, 0 | 20, 0 |
| 音乐训练时长(年) | 9.15(5.25) | ||
| 音乐训练初始年龄(岁) | 12.35(4.66) | ||
| MET测试分数 | 69.62(9.76) | 79.66(5.50) | 69.23(7.28) |
| LexTALE测试分数 | 71.74(6.82) | 53.75(7.82) | 53.63(7.63) |
注:括号内的数字为标准差。 |
2.2 实验材料
Stroop实验分为中英两个版本。实验刺激如表2 所示,共有四个颜色词,中文为红、黄、蓝、绿,英文为red、yellow、blue、green。刺激分为颜色−语义一致(如红色的“红”或“red”)、颜色−语义不一致(如绿色的“红”或“red”)和无关中性词(如红色的“牵”或“desk”)三种条件。通过当代美国英语语料库COCA(https://www.english-corpora.org/coca/)和中文文本计算网站(http://lingua.mtsu.edu/chinese-computing)对材料的词频进行统计。统计结果表明中英文刺激词频在色词和无关中性词之间没有显著差异[中文: t(3.87)=2.19, p=0.10; 英文: t(3.47)=−0.62, p=0.57]。每种颜色在每种条件下的刺激重复5次,每种语言条件下的Stroop任务有60个试次。
表2 Stroop任务中实验刺激 |
| 语言 | 色词一致 | 色词不一致 | 无关中性词 |
| 中文 | 红(红) | 绿(红) | 牵(红) |
| 黄(黄) | 蓝(黄) | 趁(黄) | |
| 蓝(蓝) | 红(蓝) | 宫(蓝) | |
| 绿(绿) | 黄(绿) | 涂(绿) | |
| 英文 | Red(红) | Green(红) | Desk(红) |
| Yellow(黄) | Blue(黄) | Map(黄) | |
| Blue(蓝) | Red(蓝) | Class(蓝) | |
| Green(绿) | Yellow(绿) | Family(绿) |
注:括号内为刺激的字体颜色。 |
2.3 实验程序
实验在安静实验室进行,刺激呈现与数据收集使用E-Prime3.0软件完成。刺激随机呈现于屏幕中央,字体大小为48号,背景为灰色。汉字采用宋体,英文单词采用Times New Roman字体。实验分为中文颜色词命名和英文颜色词命名任务,任务先后顺序在被试间平衡。在实验中,被试需忽视语义信息判断字体颜色,键盘顶端的“1”“2”“3”“4”四个数字分别对应一种颜色,并贴着相应的色块。刺激呈现流程如下:首先在屏幕中央呈现500 ms的注视点“+”,随后呈现3000 ms刺激,被试在此期间需尽快做出反应,之后呈现1000 ms随机空屏。正式实验前,被试需完成5个练习试次,达到100%正确率后进入正式实验。被试在正式实验中不会获得正误反馈。
2.4 数据分析
采用R软件进行数据统计分析,采用lme4包拟合混合效应模型。依据前人标准删除正确率低于90%的被试(孙桂芹 等, 2021),低水平对照组中有一人数据被排除。由于三组被试的平均正确率较高,产生了天花板效应(高水平二语组: 98%; 高水平音乐组: 97%; 低水平对照组: 96%),故不做正确率分析。反应时数据剔除错误反应及超出均值±2个标准差的数据(Li et al., 2017),约4%的数据被删除。为减少异常值影响并使数据更接近正态分布,对反应时数据进行对数转换后再作为因变量(马拯 等, 2022)。根据Stroop任务语言类型的不同,分别建立了中文和英文任务的混合效应模型。首先,将组别(高水平音乐组、高水平二语组、低水平对照组)、刺激条件(色词一致、色词不一致、无关中性词)及其交互作用纳入固定效应。对于显著的交互作用,采用emmeans包进行简单效应分析,并采用Tukey方法校正事后检验的p值。在考察混合模型的随机结构时,同时包括被试的随机斜率和随机截距,其中被试和项目作为随机因子。另外,为控制被试二语水平以及音乐经验对实验结果造成的影响,将标准化后的LexTALE和MET得分作为协变量放入模型中。通过比较不同随机效应结构的模型(如是否包含随机斜率),并基于赤池信息量准则(Akaike information criterion, AIC)选择了AIC值最小的模型作为最优模型。
3 结果
通过剔除错误反应与2个标准差之外的数据,高水平二语组、高水平音乐组、低水平对照组在Stroop任务的平均反应时分别为:673 ms,633 ms和609 ms。三组被试在不同语言类型和刺激条件下的反应时如表3 所示。三组被试的Stroop效应量如图1 所示。
表3 三组被试在一语和二语Stroop任务中不同刺激条件下的反应时及Stroop效应量(ms) |
| 组别 | 语言 | 刺激条件 | Stroop效应量 | ||
| 色词一致 | 色词不一致 | 无关中性词 | |||
| 低水平对照组 (n=19) | 中文 | 597(68) | 644(90) | 603(70) | 46(57) |
| 英文 | 591(77) | 611(80) | 605(76) | 20(38) | |
| 高水平二语组 (n=20) | 中文 | 649(66) | 738(72) | 662(66) | 89(55) |
| 英文 | 656(74) | 674(67) | 661(77) | 18(40) | |
| 高水平音乐组 (n=20) | 中文 | 607(72) | 687(97) | 615(72) | 80(54) |
| 英文 | 620(91) | 639(94) | 630(88) | 19(37) | |
注:括号内的数字为标准差。 |
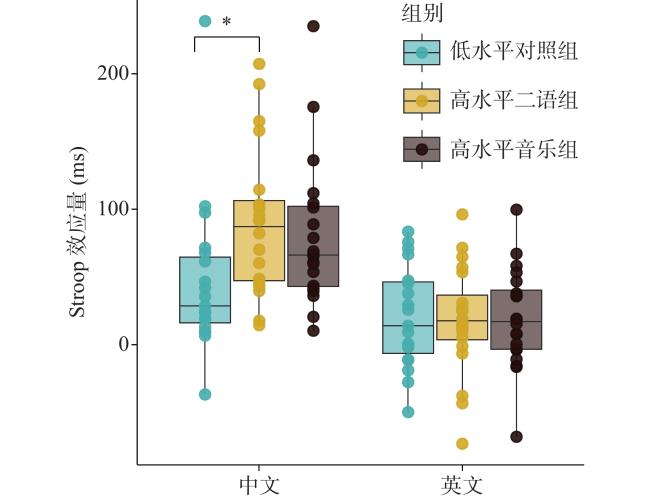
中英文Stroop任务的混合效应模型的拟合结果如表4 所示。结果显示,对于中文任务,刺激条件的主效应显著[χ2(2)=57.29, p<0.001],组别和刺激条件之间的交互作用显著[χ2(4)=9.63, p<0.05]。然而在英文Stroop任务中,组别的主效应[χ2(2)=3.57, p=0.17],刺激条件主效应[χ2(2)=3.49, p=0.17]和组别与刺激条件之间的交互效应[χ2(4)=0.35, p=0.99]都不显著。为进一步探究中文任务中的交互作用,首先对每组被试内部的刺激条件进行配对比较。结果显示,高水平二语组和高水平音乐组在色词不一致条件下的反应时显著长于其他两种刺激条件(ps<0.001),表现出Stroop效应;而低水平对照组在三种条件间无显著差异(色词一致−色词不一致: p=0.10; 色词一致−无关中性词: p=0.92; 色词不一致−无关中性词: p=0.21)。其次对每种刺激条件下的组间反应时进行配对比较。结果显示,仅在色词不一致条件下,高水平二语组的反应时显著长于低水平对照组(β=0.14, SE=0.05, t=2.67, p<0.05),其余条件下组别之间均无显著差异(ps>0.05)。在此基础上,进一步对Stroop效应量进行方差分析。结果发现,仅在中文任务中,高水平二语组的Stroop效应量显著大于低水平对照组(p<0.05),而其他组别之间未见显著差异(ps>0.05)。
表4 混合效应模型拟合结果 |
| 固定效应 | 卡方值 | 自由度 | p |
| 中文任务 | |||
| 组别 | 4.03 | 2 | 0.13 |
| 刺激条件 | 57.29 | 2 | <0.001 |
| 组别×刺激条件 | 9.63 | 4 | 0.04 |
| 英文任务 | |||
| 组别 | 3.57 | 2 | 0.17 |
| 刺激条件 | 3.49 | 2 | 0.17 |
| 组别×刺激条件 | 0.35 | 4 | 0.99 |
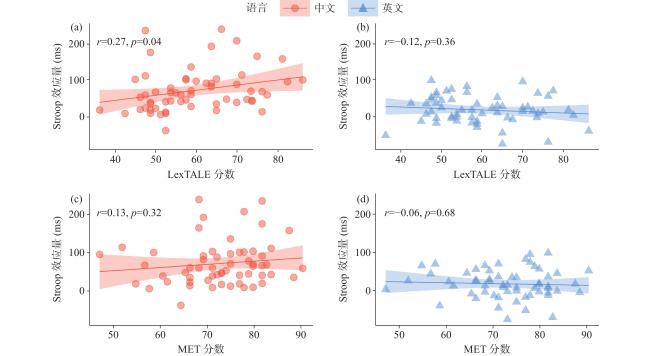
以上结果表明,二语水平会对抑制控制能力产生影响。本研究发现,与低水平对照组相比,高水平二语组在一语Stroop任务中对色词不一致时的反应时显著更长,表明其Stroop效应更强(图1 )。为进一步验证二语水平对Stroop效应的影响,对59名被试进行了皮尔逊相关性检验来探究所有被试LexTALE词汇测试得分与一语及二语Stroop效应的关系。Stroop效应量通过色词不一致条件与一致条件的反应时差值计算。结果显示,LexTALE分数与一语Stroop效应量显著正相关(图2a ; r=0.27, p<0.05),即二语水平越高,被试在一语Stroop任务中的干扰效应越强;但LexTALE分数与二语Stroop效应量无显著相关性(图2b ; r=−0.12, p=0.36)。此外,为检验音乐经验对Stroop效应的影响,分析了所有被试MET分数与一语及二语Stroop效应量的相关性(图2c , 图2d )。结果显示,MET分数与一语及二语Stroop效应量之间均无显著相关性(中文: r=0.13, p=0.32; 英文: r=−0.06, p=0.68)。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 讨论
本研究以中国英语学习者为对象,通过中英双语Stroop色词任务探究二语水平和音乐经验对抑制控制的影响。研究发现,高水平二语组在一语Stroop任务中,当颜色和语义信息不一致时,反应时间显著长于低水平对照组,表现出更强的Stroop效应。相关性分析进一步证实,LexTALE测试分数与一语Stroop效应量显著正相关,表明二语水平的提高可能导致语义信息自动激活程度增强,从而引发更大的干扰效应。但是在二语Stroop任务中,未观察到二语水平带来的影响。至于音乐经验,无论是在一语还是二语Stroop任务,高水平音乐组与其他两组的反应时均无显著差异,未表现出更强的抑制控制能力。
4.1 二语水平对抑制控制的影响:语义自动化的代价
在中文Stroop任务中,高水平二语学习者在色词不一致条件下反应时显著长于低水平二语学习者。此外LexTALE测试与Stroop效应量的正相关关系进一步支持了这一发现,表明二语水平的提高并不一定意味着降低干扰信息的能力增强,这与前人部分研究结果一致(李恒, 曹宇, 2016; 张高德, 陈飞, 2023)。李恒和曹宇发现,双语认知优势取决于双语者的二语水平,高水平双语者的抑制能力较强,而低水平双语者未表现出明显优势。但与前人不同,本研究中高水平二语者受到的干扰反而更大。一个可能的解释是,高水平二语者日常生活中频繁切换语言,提高了语言自动化程度,使大脑能够更快地识别和处理词汇。这种快速的语义激活虽在语言交流中具有优势,但在需要抑制这些自动化反应的Stroop任务中会增加认知负荷,从而延长反应时间。这与认知负荷理论相符,该理论指出过度自动化可能在信息冲突处理中导致额外的认知负担。需要说明的是,尽管高水平二语者在Stroop任务中表现出更大的干扰效应,但这同时反映了其在语义识别和自动激活方面的增强。这种能力在多语环境中尤为重要,帮助个体实现快速的信息检索,更高效地切换语言。因此,高水平二语者在Stroop任务中面临更多挑战的同时,也体现了语言处理能力的提升。
但本研究在二语Stroop任务中未发现二语水平对反应时的显著影响。这与高姗等人(2017)的发现一致,同时陈小异等人(2007)也发现中国英语学习者母语的干扰效应明显强于二语。这一结果可能有以下解释:首先,高水平二语学习者的二语能力虽然相对较高,但尚未达到语义激活的自动化阈值。这是由于所有被试均未在目标语言国家学习或沉浸式使用二语,导致二语的语义激活不足以对颜色识别产生干扰(高姗 等, 2017)。其次,二语水平的影响可能被其他认知因素,如工作记忆容量所掩盖,有研究表明工作记忆容量低的被试更容易在Stroop任务中犯错(Kane & Engle, 2003),但本研究未对被试的工作记忆进行测量,是否是工作记忆造成的个体差异还有待考察。
总之,二语水平和抑制控制的关系并非简单的正相关。二语水平的提升在某些情况下可能导致更复杂的认知挑战,只有当二语水平达到一定程度后才可能产生认知优势,但该过程也受到了诸多因素的影响,例如语言使用频率、语言环境,以及个体的语言加工偏好,这有待未来研究进一步探讨和分析。
4.2 音乐经验对抑制控制的影响:迁移效应的局限性
本研究未发现音乐经验对抑制控制的显著促进作用,这与部分研究相悖(王婷 等, 2019; 张航 等, 2023),前人研究发现,无论是声乐(侗歌)还是器乐(铜鼓)经验,音乐训练通常能提高被试在抑制控制任务中的准确率和反应速度。然而,也有研究支持本研究的发现,指出音乐经验并非在所有情况下都能显著提升抑制控制(Slevc et al., 2016; Zuk et al., 2014)。原因可能有以下三点:第一,音乐训练主要强化听觉系统,而本研究采用的是视觉通道Stroop色词任务,未直接利用音乐训练的听觉优势。未来研究可以通过结合视觉与听觉的双通道任务进一步探讨音乐训练的领域一般性作用。第二,音乐经验与抑制控制能力之间的关系也会受到音乐经验细化特征的影响,如训练起始年龄、训练类型、训练时长等。本研究中音乐组的初始训练年龄(12.35±4.66岁)已晚于音乐训练被认为对大脑可塑性产生显著影响的关键期(小于7岁)(Miendlarzewska & Trost, 2014),且大多数被试接受的是以音高为主的弦乐器训练(钢琴、古筝),而非以节奏为主的打击乐器,这可能限制了音乐训练对抑制控制的促进作用(Frischen et al., 2019)。第三,行为学指标的不敏感性也是造成该结果的潜在原因。本研究中正确率的天花板效应和反应时的微弱差异可能掩盖了音乐经验的真实影响。例如,陈洁佳等人(2020)通过脑电技术发现音乐组的脑电诱发波幅(N2和P3)显著大于对照组,尽管两组在行为指标上未显示差异。这表明未来研究需要结合更敏感的神经生理指标才能更准确揭示音乐训练对抑制控制能力的影响。虽然本研究未观察到音乐经验与抑制控制能力提升之间的显著联系,但研究结果并不否定音乐经验对认知功能的潜在益处。例如,本研究发现音乐组在中文任务色词一致条件下的反应时显著快于不一致条件,表现出Stroop效应,而对照组未观察到类似现象。这表明音乐经验可能增强了语义信息的激活,从而促进了语言加工。
总体来看,双语水平和音乐经验对抑制控制的影响存在显著差异,这种差异也体现在迁移效应上,即经验的迁移在与其核心活动高度相似的任务中表现最为显著(Bialystok & DePape, 2009)。Stroop色词任务的核心是语义信息的激活与抑制,而双语经验直接涉及语言加工,因此更能影响与语言相关的认知能力。相比之下,音乐经验主要侧重于时间感知和节奏处理,其在语言任务中的迁移效果可能相对有限。这也进一步反映了两种经验在认知加工作用机制上的差异。未来研究可进一步探究二者的神经机制差异,为理解其迁移效应提供更直接的证据。
5 结论
本研究通过中英双语Stroop色词任务探讨了二语水平和音乐经验对中国英语学习者抑制控制能力的影响。结果揭示了两个发现:第一,高水平二语学习者比低水平二语学习者展现出更强的Stroop效应,表明随着二语水平的提高,学习者对词汇的敏感度和语义激活程度增强,进而干扰效应增加。第二,本研究中音乐经验未能显著提高抑制控制能力,这可能与加工通道不对称、音乐经验特征及实验手段的限制有关。