
1 引言
语言文字是社会信息传递、思想表达和情感交流的重要工具。新时代教育背景下,我国全面加强和发展国家通用语言文字事业,提高民族地区国家通用语言文字普及程度,促进民族同胞语言相通、心灵相通。各民族地区在传承发展民族语言文化的同时,积极学习国家通用语言文字。新疆维吾尔自治区少数民族人口众多,是我国重要的双语教育区。虽然维吾尔族学生从基础教育阶段开始学习汉语,但目前并未达到“民汉兼通”的理想目标(杨群 等, 2021)。相比维吾尔语(以下简称“维语”),汉语书写系统具有独特性,导致维语学生汉语学习存在困难。维语属于拼音文字,具有系统的形−音对应规则,文本中存在词间空格标记词边界信息。而汉语属于表意文字,形−音对应规则不系统,词汇语义具有模糊性(如“从小学”可以是“从小/学”或“从/小学”),并且文本中没有词间空格标记词边界信息,仅能依靠句中的标点符号来表示语义单元和停顿(李馨, 2018; 梁菲菲 等, 2024; 梁菲菲 等, 2023; Li & Pollatsek, 2020; Liang et al., 2023),为汉语词切分和词汇识别增加难度(梁菲菲, 2022; Zang et al., 2011)。因此,汉语读者十分依赖自上而下的信息(Li et al., 2009),如在长期汉语阅读和学习中内隐习得的高水平语言学线索(梁菲菲, 2022; Rayner et al., 2005)。
词素的特性(如词素位置概率)可以为读者提供自上而下的词边界的信息,是汉语阅读过程中一种有效的词切分线索(曹海波 等, 2023; 梁菲菲 等, 2024; 梁菲菲 等, 2016; Liang et al., 2023; Yen et al., 2012)。词素位置概率是指某个汉字用于词首或词尾的次数占该汉字组成的所有词数量的比例,例如,在SUBTLEX-CH语料库中(Cai & Brysbaert, 2010),“州”字可以组成39个双字词,用在词首(如“州长”、“州府”)和词尾(如“各州”、“杭州”)的个数分别为5个和34个,其词首概率和词尾概率分别为12.8%和87.2%,可见“州”字的位置信息更多指向词尾。
曹海波等人(2023)结合词汇判断任务和眼动追踪技术,考察在不同词频条件下词素位置概率对汉语词汇识别和阅读的影响,结果证实词素位置概率信息是汉语词切分和词汇识别的有效线索,但词素位置概率的作用受整词词频的调节,在低频词加工中表现出更大优势。这可能是由于读者加工不同词频的目标词时,采取的加工策略不同,对高频词进行整体加工,更关注目标词整体,对低频词进行局部加工,其词素信息得到重视(Chu & Leung, 2005)。
新词对于读者来说属于极端低频词,读者在汉语阅读中可以借助新词的首、尾词素位置概率信息进行词切分,构建新词语义表征(梁菲菲 等, 2024)。Liang等人(2015, 2017)通过编造三种不同类型的新词(一致条件:首、尾词素位置概率与实际一致,如“挑尔”;不一致条件:首、尾词素位置概率与实际不一致,如“子左”;控制条件:首、尾词素位置概率均在50%,如“皮合”),为目标词构造6个句子语境,考察词间空格和词素位置概率在儿童和成人读者新词学习中的作用,结果发现词间空格和词素位置概率均独立影响读者词汇习得,分别作用于词汇加工的早期和晚期。并且与成人相比,儿童利用尾词素位置概率的能力更低(Liang et al., 2023)。可见,词素位置概率信息在汉语词切分和词汇识别中的作用受读者阅读经验的影响。
泰语字母本身携带一定的位置信息,因此泰语读者也能够利用字母本身携带的位置信息进行词切分(梁菲菲 等, 2022)。当目标词的词首字母常用于词首、词尾字母常用于词尾时,泰语读者对目标词的注视时间显著减少,首次注视位置更靠近词中心(Kasisopa et al., 2013, 2016),表明词素位置信息可以促进词汇识别和眼跳定位。
维语读者可以在双语学习过程中逐渐积累一定的汉语阅读经验和词汇知识,那他们能否利用词素位置概率信息促进汉语词切分和词汇识别,是否会表现出与汉语母语读者一致的加工模式?这是本研究考察的第一个问题。
在阅读伴随词汇学习中,读者往往基于多个语境学习新词,是一个渐进和累积的过程(Joseph et al., 2014),对目标词也由陌生逐渐转为熟悉,那么随着目标词学习次数的增加,维语读者在阅读过程中的词素位置概率效应是否会发生变化?这是本研究考察的第二个问题。
而目前基于汉语的研究,仅在注视时间相关指标上发现词素位置概率的作用,词素位置概率是否会影响维语读者眼跳目标的选择和定位?这是本研究考察的第三个问题。
2 研究方法
2.1 被试
天津师范大学72名维语大学生,年龄范围为18~24岁(平均年龄20.01±1.60岁),母语为维语。所有被试视力或矫正视力正常,实验结束后将获得一定劳务费。
采用语言经历调查问卷(Language History Questionnaire, 简称LHQ3)(Li et al., 2020)和三分钟快速朗读任务对维语读者的语言经历和汉语阅读流畅性进行测查,结果显示本实验被试具有一定的汉语水平(见表1 )。
表1 被试语言背景信息和汉语阅读流畅性测试结果(M±SD) |
| 指标 | 汉语 | 维语 |
| 累计使用年数 | 14.10±2.94 | 19.38±1.99 |
| 沉浸率 | 0.70±0.11 | 0.85±0.08 |
| 主导度 | 0.61±0.13 | 0.40±0.11 |
| 熟练度 | 0.75±0.13 | 0.68±0.19 |
| 流畅性(字/3分钟) | 415.3±74.2 |
2.2 实验设计
采用2(词素位置概率:HH目标词、LL目标词)×6(学习次数:1~6)的被试内实验设计。HH、LL目标词的筛选见实验材料。
2.3 实验材料
根据Cai和Brysbaert(2010)编制的语料库(SUBTLEX-CH),筛选出80个汉字,其中位于双字词词首概率高的汉字(以下简称为“首高字”)、词首概率低的汉字(以下简称为“首低字”)、词尾概率高的汉字(以下简称为“尾高字”)、词尾概率低的汉字(以下简称为“尾低字”)各20个字。在控制字频、笔画数以及构词力的前提下,将其两两组合成40个假词,其中一半的假词是由“首高字”和“尾高字”组成(即“HH词”),另一半假词是由“首低字”和“尾低字”组成(即“LL词”)。
对40个假词进行评定:(1)在《现代汉语词典》和汉语字词语料库中均不存在;(2)请不参加后续正式实验的15名大学生完成真假词判断任务:呈现编制的40个目标词和另外40个真词,要求被试圈出所有认识的真词。最终选出其中32个(16对)假词作为实验目标词,其基本信息见表2 。
表2 目标词信息(M±SD) |
| 信息类型 | 目标词类型 | ||
| 首高尾高(HH词) | 首低尾低(LL词) | ||
| 首字 | 词首概率 | 0.94±0.04 | 0.10±0.03 |
| 构词力 | 23.75±9.76 | 23.88±10.89 | |
| 笔画数 | 7.00±2.56 | 7.31±2.44 | |
| 字频(次/百万字) | 12.61±14.43 | 12.56±13.55 | |
| 尾字 | 词尾概率 | 0.94±0.04 | 0.12±0.04 |
| 构词力 | 26.19±11.11 | 24.50±9.43 | |
| 笔画数 | 9.69±2.30 | 9.00±2.53 | |
| 字频(次/百万字) | 7.23±11.16 | 7.76±11.10 | |
| 整词 | 构词力 | 49.94±15.62 | 48.38±10.38 |
| 笔画数 | 16.69±3.84 | 16.31±3.50 | |
经统计检验结果发现,两类目标词首字的词首概率差异显著[t(15)=56.43, p<0.05],首字的构词力、笔画数以及字频差异不显著(ps>0.05);两类目标词尾字的词尾概率差异显著[t(15)=61.92, p<0.05],尾字的构词力、笔画数以及字频差异不显著(ps>0.05);两类目标词的整词构词力和笔画数差异不显著(ps>0.05)。
为目标词编造句子框架,每个目标词均有6个实验句,将其描述为日常生活中常见的语义类别,用于赋予目标词意义。每个语义类别包含一对目标词(即HH词和LL词各一个)。实验总共包括16个语义类别:防疫用品、体育项目、职业、建筑、交通工具、食物、化妆品、服饰、厨具、电子设备、文具、水果、乐器、饮品、动物、植物。总共编制192个实验句,所有目标词位于句中,句长21~28个汉字(M=25.08),且目标词的首字和尾字与相邻汉字均不构成双字词,实验句示例见表3 。
表3 实验句示例 |
| 句子编号 | 实验句 |
| 1 | 园艺师花重金购入牵堡打造精品观光园,吸引了众多旅客。 |
| 2 | 任凭风吹雨打,悬崖峭壁上那株牵堡依然坚韧不拔地长在那里。 |
| 3 | 多雨潮湿的草地和覆盖腐殖质的岩石变成牵堡迅速生长的温床。 |
| 4 | 仔细观察可以发现牵堡内部的花蕊仿佛是一只展翅欲飞的鸽子。 |
| 5 | 云南有一种特产就是选用牵堡成熟后的花朵和茎叶作为馅料。 |
| 6 | 如果想美化室内环境,可以在花盆里种一些牵堡摆在客厅里。 |
| 语义类别选择题 | 请选择:“牵堡”属于以下哪个类别?体育项目 植物 厨具 文具 |
注:加粗部分为目标词,下划线为语义类别选择题正确答案。 |
请25名不参加正式实验的维语大学生对句子难度进行5点评分(1=“非常简单”,5=“非常困难”),所有实验句难度的平均数为1.39(SD=0.17),表明所有实验句均简单且易理解。请28名不参加正式实验的大学生对句子通顺性进行5点评定(1=“非常不通顺”,5=“非常通顺”),所有实验句通顺性的平均数为4.19(SD=0.36),表明所有实验句都非常通顺。
拉丁方平衡后形成2个组块,每个组块有32个目标词,每个目标词有6个句子语境,部分句子后附有阅读理解判断题和语义类别选择题,共192个实验句,64个判断题和32个语义类别选择题。
2.4 实验仪器
采用SR Research公司EyeLink 1000Plus眼动仪记录被试阅读时的眼动轨迹,采样率为1000 Hz,屏幕刷新率为60 Hz,分辨率为1024×768。被试眼睛与屏幕之间的距离为71 cm。所有实验材料以宋体20号字呈现,每个汉字的大小为27×27像素,每个字的视角约为0.96°。
2.5 实验程序
被试先完成纸质版语言经历调查问卷,然后进入实验室,坐在距屏幕71 cm处,调整到舒适姿势。待被试充分理解指导语后,按空格键阅读6个练习句,以便熟悉整个实验流程。练习完成后开始正式实验,被试随机阅读其中一个组块的实验句,所有句子随机呈现,实验持续30~35分钟。
2.6 结果
基于以往研究筛选数据,删除注视时间小于80 ms或大于1200 ms的注视点(Rayner, 2009),此外按照以下标准删除无效数据(Liang et al., 2017):(1)因被试过早按键或误触按键导致句子未读完;(2)因被试头动等偶然因素导致数据丢失(约占0.8%);(3)实验句仅有一半的内容有注视点,或整句注视点少于5个。(4) 3个标准差以外的数据(约0.1%)。
基于R语言(R Development Core Team, 2014)环境下的线性混合模型(linear mixed model, LMM)处理和分析所有的眼动实验数据。时间类的连续变量指标(如首次注视时间)先进行Log线性转换,再纳入LMM模型进行分析;二分变量数据(如回视比率)采用GLMM模型进行分析。分析时采用最大化随机效应结构模型(maximal random effects structure)(Barr et al., 2013),将目标词的学习次数(1~6)、词素位置概率以及两者的交互作用作为固定因子进行分析,其中学习次数作为连续变量,对其进行中心化处理,将被试和项目定义为交叉随机效应纳入模型(Meteyard & Davies, 2020)。当模型拟合不成功时,依次去除因子之间的相关、项目的交互作用、被试的交互作用和斜率,直到模型拟合成功(Liu et al., 2021)。
2.6.1 阅读理解题和语义类别题正确率
阅读理解题正确率的范围为81.3%~98.4%(M=92.8%, SD=25.8%),表明读者都认真阅读并已理解实验材料。语义类别选择题正确率范围为81.3%~100%(M=97.4%, SD=15.8%),表明被试能较好判断目标词的语义类别。
2.6.2 眼动指标结果
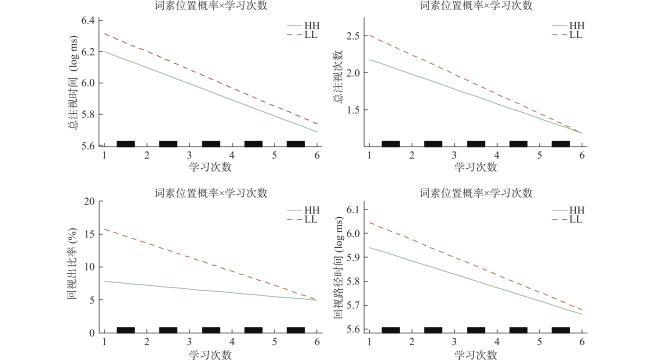
眼动指标的描述统计结果见表4 和图1 ,线性混合模型分析结果见表5 和图2 。
表4 眼动指标的描述统计结果(M±SD) |
| 眼动指标 | 目标词 | 学习次数 | |||||
| 1 | 2 | 3 | 4 | 5 | 6 | ||
| 首次注视时间(ms) | HH | 279±109 | 267±95 | 258±81 | 251±77 | 258±92 | 252±83 |
| LL | 283±117 | 269±105 | 263±94 | 260±84 | 260±90 | 254±89 | |
| 凝视时间(ms) | HH | 446±274 | 368±228 | 333±182 | 319±150 | 323±168 | 318±167 |
| LL | 471±321 | 381±244 | 353±195 | 337±183 | 338±183 | 329±181 | |
| 总注视时间(ms) | HH | 766±470 | 509±339 | 447±286 | 423±274 | 414±242 | 406±273 |
| LL | 890±566 | 567±388 | 505±321 | 476±316 | 440±278 | 431±273 | |
| 回视路径时间(ms) | HH | 573±437 | 425±323 | 379±269 | 390±290 | 374±239 | 373±245 |
| LL | 678±546 | 479±387 | 430±333 | 416±294 | 403±319 | 389±300 | |
| 回视入比率 | HH | 0.37±0.48 | 0.20±0.40 | 0.17±0.37 | 0.17±0.38 | 0.16±0.36 | 0.15±0.36 |
| LL | 0.40±0.49 | 0.24±0.42 | 0.23±0.42 | 0.20±0.40 | 0.16±0.36 | 0.17±0.37 | |
| 回视出比率 | HH | 0.15±0.35 | 0.09±0.29 | 0.07±0.25 | 0.12±0.32 | 0.09±0.29 | 0.11±0.31 |
| LL | 0.21±0.41 | 0.13±0.33 | 0.12±0.32 | 0.13±0.34 | 0.10±0.30 | 0.11±0.31 | |
| 总注视次数 | HH | 2.70±1.79 | 1.83±1.29 | 1.59±1.04 | 1.56±1.02 | 1.51±0.93 | 1.51±0.99 |
| LL | 3.16±2.11 | 2.03±1.47 | 1.81±1.20 | 1.72±1.17 | 1.58±1.07 | 1.59±1.07 | |
| 首次注视位置 | HH | 0.85±0.52 | 0.86±0.53 | 0.89±0.54 | 0.87±0.54 | 0.88±0.53 | 0.88±0.54 |
| LL | 0.82±0.51 | 0.85±0.52 | 0.87±0.51 | 0.85±0.54 | 0.85±0.52 | 0.86±0.53 | |
| 单一注视 首次注视位置 | HH | 1.12±0.48 | 1.04±0.48 | 1.04±0.52 | 1.04±0.50 | 1.03±0.51 | 1.03±0.50 |
| LL | 0.98±0.47 | 1.01±0.49 | 1.02±0.47 | 0.97±0.50 | 1.00±0.49 | 0.99±0.51 | |
| 多次注视 首次注视位置 | HH | 0.78±0.51 | 0.71±0.52 | 0.74±0.51 | 0.69±0.52 | 0.72±0.51 | 0.71±0.53 |
| LL | 0.78±0.51 | 0.74±0.51 | 0.76±0.51 | 0.75±0.56 | 0.69±0.50 | 0.73±0.53 | |
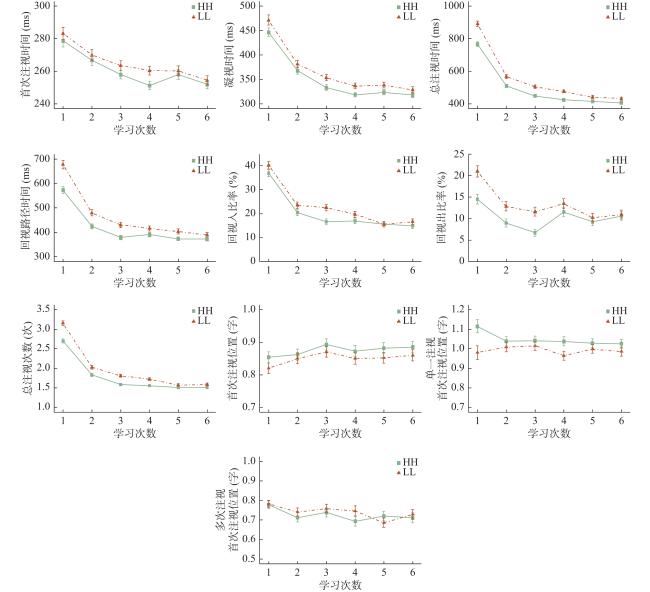
统计结果显示:
(1)词素位置概率主效应在总注视时间、回视路径时间、总注视次数、回视入比率、回视出比率、首次注视位置、单一注视首次注视位置指标上显著(|t|s>2.37, ps<0.05),相比LL词,被试对HH词的注视时间更短,总注视次数更少,回视比率更低,平均首次注视落点位置更靠近词中心。
(2)学习次数主效应在首次注视时间、凝视时间、总注视时间、回视路径时间、总注视次数、回视入比率、回视出比率、多次注视首次注视位置指标上显著(|t|s>2.56, ps<0.05),随着对目标词学习次数的增加,被试在目标词上的注视时间和总注视次数逐渐减少,回视比率逐渐降低,注视位置逐渐趋近词中心位置。
(3)词素位置概率和学习次数的交互作用在总注视时间、回视路径时间、总注视次数、回视出比率指标上显著(|t|s>1.84, ps<0.05),随着学习次数的增加,被试对所有目标词的注视时间、总注视次数和回视出比率逐渐减少,其中LL词的注视时间、总注视次数和回视比率降速更快。
3 讨论
本研究以维语(属于具有词间空格的拼音文字)为母语、以汉语为二语的维语读者为研究对象,考察词素位置概率信息在其汉语阅读词汇学习中的作用,主要结果发现,词素位置概率影响维语读者汉语阅读的词汇识别,尤其反映在词汇加工晚期阶段;同时随着目标词学习次数的增加,词素位置概率的作用逐渐减小。
表5 注视时间指标线性混合模型分析结果 |
| 眼动指标 | b | SE | t | 95%CI | |
| 首次注视时间 | 截距 | 5.56 | 0.02 | 296.10 | [5.52, 5.60] |
| 词素位置概率 | 0.01 | 0.01 | 0.85 | [−0.02, 0.04] | |
| 学习次数 | −0.02 | 0.002 | −6.61 | [−0.02, −0.01] | |
| 词素位置概率×学习次数 | −0.0002 | 0.004 | −0.04 | [−0.01, 0.01] | |
| 凝视时间 | 截距 | 5.89 | 0.03 | 191.49 | [5.83, 5.95] |
| 词素位置概率 | 0.03 | 0.02 | 1.59 | [−0.01, 0.07] | |
| 学习次数 | −0.05 | 0.005 | −10.73 | [−0.06, −0.04] | |
| 词素位置概率×学习次数 | 0.0001 | 0.01 | 0.01 | [−0.01, 0.01] | |
| 总注视时间 | 截距 | 6.42 | 0.05 | 118.39 | [6.31, 6.53] |
| 词素位置概率 | 0.13 | 0.03 | 4.90 | [0.08, 0.19] | |
| 学习次数 | −0.11 | 0.01 | −10.27 | [−0.13, −0.09] | |
| 词素位置概率×学习次数 | −0.01 | 0.01 | −1.84 | [−0.03, 0.00] | |
| 回视路径时间 | 截距 | 5.86 | 0.03 | 205.40 | [5.81, 5.92] |
| 词素位置概率 | 0.07 | 0.01 | 5.85 | [0.05, 0.09] | |
| 学习次数 | −0.06 | 0.01 | −7.63 | [−0.08, −0.05] | |
| 词素位置概率×学习次数 | −0.02 | 0.01 | −2.41 | [−0.03, 0.00] | |
| 回视入比率 | 截距 | −0.62 | 0.13 | −4.82 | [−0.88, −0.37] |
| 词素位置概率 | 0.24 | 0.10 | 2.37 | [0.04, 0.44] | |
| 学习次数 | −0.24 | 0.03 | −8.43 | [−0.29, −0.18] | |
| 词素位置概率×学习次数 | −0.02 | 0.03 | −0.67 | [−0.07, 0.04] | |
| 回视出比率 | 截距 | −2.27 | 0.10 | −22.80 | [−2.46, −2.07] |
| 词素位置概率 | 0.31 | 0.06 | 5.12 | [0.19, 0.42] | |
| 学习次数 | −0.09 | 0.03 | −2.87 | [−0.15, −0.03] | |
| 词素位置概率×学习次数 | −0.10 | 0.03 | −2.92 | [−0.17, −0.03] | |
| 总注视次数 | 截距 | 1.88 | 0.06 | 29.49 | [1.76, 2.01] |
| 词素位置概率 | 0.20 | 0.02 | 9.89 | [0.16, 0.24] | |
| 学习次数 | −0.23 | 0.03 | −9.04 | [−0.28, −0.18] | |
| 词素位置概率×学习次数 | −0.06 | 0.01 | −5.57 | [−0.09, −0.04] | |
| 首次注视位置 | 截距 | 0.87 | 0.01 | 64.99 | [0.85, 0.90] |
| 词素位置概率 | −0.03 | 0.01 | −2.57 | [−0.05, −0.01] | |
| 学习次数 | 0.01 | 0.004 | 1.43 | [0.00, 0.01] | |
| 词素位置概率×学习次数 | −0.0005 | 0.01 | −0.01 | [−0.01, 0.01] | |
| 单一注视 首次注视位置 | 截距 | 1.02 | 0.01 | 128.45 | [1.00, 1.03] |
| 词素位置概率 | −0.05 | 0.02 | −3.10 | [−0.08, −0.02] | |
| 学习次数 | −0.01 | 0.005 | −1.43 | [−0.02, 0.00] | |
| 词素位置概率×学习次数 | 0.01 | 0.01 | 0.84 | [−0.01, 0.02] | |
| 多次注视 首次注视位置 | 截距 | 0.76 | 0.02 | 41.34 | [0.72, 0.79] |
| 词素位置概率 | 0.01 | 0.01 | 0.90 | [−0.01, 0.04] | |
| 学习次数 | −0.01 | 0.004 | −2.56 | [−0.02, 0.00] | |
| 词素位置概率×学习次数 | −0.0006 | 0.01 | −0.01 | [−0.01, 0.01] |
注:粗体表示差异显著,下划线表示差异边缘显著。 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3.1 词素位置概率信息在维语读者汉语阅读中的作用
本研究的实验结果与以往研究一致(曹海波 等, 2023; 曹海波 等, 2022; 连坤予 等, 2021; 梁菲菲, 2022; Kasisopa et al., 2013; Liang et al., 2015),维语读者对HH词的加工更容易,在此类目标词上注视时间更短,回视入和回视出的比率更低,总注视次数更少,注视位置也更靠近目标词中心位置。这表明维语读者在长期的汉语阅读中,已积累较为丰富的汉语阅读经验,并具备较高的汉语阅读水平,表现出与汉语母语读者一致的加工模式,能充分利用词素位置概率线索来促进汉语阅读和引导眼跳定位。
汉语读者的阅读知觉广度包括当前注视词左侧一个汉字和右侧三个汉字(Yan et al., 2015)。根据Li和Pollatsek(2020)提出的汉语阅读整合模型(CRM模型),读者阅读过程中,将激活其知觉广度范围内的所有汉字,汉字组成的所有可能的词也得到激活。当读者注视目标词时,汉字视觉信息的输入促进汉字的激活,汉字本身的位置概率信息也得到激活,词素位置信息激活程度与该汉字所处位置的概率有关,词素位置概率越高,其激活程度越高(曹海波 等, 2022)。
本研究同时操纵目标词的首字和尾字的词素位置概率,构造两类目标词,一类为由高词首、高词尾位置概率汉字组成的目标词(HH词),另一类为低词首、低词尾位置概率汉字组成的目标词(LL词)。虽然所有的目标词是词典中不存在的假词,但是由于HH词的首字和尾字均是常用于词首和词尾的汉字,其在目标词中所处位置与其本身携带的位置信息一致,也符合读者的心理预期,因此,读者对HH词的激活更快、更容易,也能快速从句子中将其识别和切分出来;而LL词的首字和尾字均是不常用在词首和词尾的汉字,其在目标词中所处位置与其本身携带的位置信息并不一致,与读者的心理预期冲突,需要消耗读者额外的注意资源,因此加工此类目标词较慢。
与Liang等人(2017)的研究结果一致的是,本研究发现词素位置概率效应主要出现在词汇加工晚期阶段(表现在总注视时间、回视路径时间等指标),这可能是由于,在阅读过程中,读者先基于已习得的汉字位置概率信息进行词切分,当新词中汉字固有的位置信息与语境提供的位置信息一致时,该词的识别更快;当新词中汉字的位置信息与语境提供的词切分线索矛盾时,读者容易产生认知冲突,需要花额外时间修正并重新完成词切分和词汇识别(梁菲菲 等, 2024)。
3.2 词汇学习对维语读者汉语阅读中词素位置概率效应的影响
本研究发现,随着目标词学习次数的增加,读者对目标词的注视时间不断减少,回视入和回视出比率逐渐降低,总注视次数也随之减少,并且在前两次学习中注视时间下降最快,这与以往研究结果一致(Han et al., 2024),也符合联结主义模型提出的假设,维语读者在第一次学习时就已经根据语境信息建立目标词的语义和词形的联结,并且随着学习的深入,不断巩固词形与语义的联结,因此个体学习变化的幅度会逐渐减小,趋于渐近值(Harm & Seidenberg, 1999)。
本研究还发现,新词学习的次数会影响维语读者汉语阅读过程中的词素位置概率效应。随着学习次数的增加,读者对两类目标词的注视时间、回视出比率和总注视次数均出现减少趋势,而LL词的变化幅度更明显。也就是说越到目标词学习的后期,词素位置概率效应越小。这与Liang等人(2017)的研究结果一致,其研究发现词素位置概率效应仅出现在新词学习阶段,而在测试阶段没有发现。这也可以用联结主义模型的观点来解释(Harm & Seidenberg, 1999),随着目标词学习次数的增加,到目标词学习后期,维语读者已经对目标词形成较为稳定的词形和语义的联结,无需再利用词素位置概率信息,可以直接通过词形激活语义,进而完成词汇识别。
4 结论
本研究条件下发现:(1)词素位置概率影响维语读者汉语阅读的词汇识别,主要表现在词汇加工晚期阶段;(2)随着目标词学习次数的增加,词素位置概率的作用逐渐减小;(3)词素位置概率信息可以有效引导维语读者汉语阅读词汇学习中眼跳目标的选择和定位。