
1 引言
近年来,随着智能移动终端的迅猛发展,智能手机已经成为人们日常生活中不可或缺的一部分。截至2025年2月,全球智能手机用户总数已达57.8亿,占全球人口的70.5%(Digital Reports, 2025)。此外,《第55次中国互联网络发展状况统计报告》显示截至2024年12月,我国手机网民规模达11.05亿人,其中青少年用户就有1.43亿(中国互联网络信息中心, 2025)。北京大学发布的《95后手机使用心理与行为白皮书》(https://www.psy.pku.edu.cn/xwzx/xyxw/50132psy317324.htm)显示95后群体日均手机使用时长达到8.33小时。这些数据表明,在中国青少年群体中,智能手机已超越传统意义上的通讯工具范畴,深度融入其日常生活。
智能手机的普及以及青少年频繁的手机使用引发了研究者对过量手机使用的研究。目前,过量手机使用行为通常被两个同义词所描述:一是“问题性手机使用”,二是“智能手机成瘾”(苏双 等, 2014; Kalaitzaki et al., 2024)。由于“成瘾”一词在描述手机使用行为时尚未形成普遍共识,且《精神障碍诊断与统计手册(第五版)》(Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Association, 2013)和《国际疾病分类(第十一版)》(International Classification of Diseases, 11th ed.; World Health Organization, 2022)均未将手机使用问题纳入其中,因此本研究选择采用“问题性手机使用”这一术语。问题性手机使用(problematic mobile phone use, PMPU)指的是过度且不受控制的,对个人日常生活产生不利影响的手机使用行为(Billieux, 2012)。
青少年正处于身体快速发展和心理成熟的关键阶段,自我控制能力相对薄弱,对智能手机的依赖性更强,因此更容易受到其负面影响(于晓琪 等, 2021)。研究表明,青少年频繁使用手机进行社交可能导致时间与金钱的过度消耗,并诱发抑郁、焦虑、压力增大及自杀倾向等心理健康问题(Jun, 2016)。此外,过度使用手机还会造成视力下降、睡眠质量下降及认知功能受损等不良后果(Chu et al., 2023; Muhammed & Taha, 2024; Rathakrishnan et al., 2021)。在教育层面,PMPU占用了大量学习时间,容易引发学业拖延、学习效率下降乃至学业失败等消极结果(Samaha & Hawi, 2016)。因此,系统评估青少年群体的PMPU水平,不仅有助于早期识别高风险个体、开展心理干预,也为学校心理健康教育与学生学习管理提供重要的实证依据。
目前,PMPU的评估仍主要依赖于传统量表。然而,此类测评工具在施测效率与应答负担方面仍存在一定局限。现有的PMPU量表如智能手机成瘾量表(33项; Kwon et al., 2013)、问题性手机使用问卷(30项; Billieux et al., 2008)、手机问题使用量表(27项; Bianchi & Phillips, 2005)以及手机成瘾类型量表(26项; Liu, Xu, et al., 2022)均包含较多题项。在单一变量的研究中,此类题量尚属合理,但在多变量联合测量或大规模群体施测的研究情境中,研究者通常需同时施测多个量表,被试作答时间显著延长,认知负荷增加,容易导致应答疲劳、测量误差上升及数据质量下降等问题。因此,开发一种兼具高测量效率与精确度,并能够适应大规模与多场景施测需求的新型测评工具,已成为当前研究的重要方向。
随着项目反应理论(item response theory, IRT)的发展,计算机化自适应测验(computerized adaptive testing, CAT)已经被证明可以显著提高测量效率,应对大规模施测(Segall, 2005)。CAT是一种基于计算机技术的现代测验方法,通过动态调整测验内容以适应被试的能力水平,从而实现高效、精准的测量。目前,已有其他领域的研究者开发出了多个CAT系统。Özyurt等人(2012)将CAT模块集成到名为UZWEBMAT的智能个性化在线学习系统中,用于数学概率单元的教学评估,该系统能根据学习者的实时能力估计动态选题,缩短测验长度,实现个性化评估。Ma等人(2025)开发了快速阅读的在线评估系统,该系统证明了CAT测试效率相较于随机顺序测试提高了40%,信度也高达0.9。这些系统验证了CAT技术的准确性和高效性,且可以应对大规模施测场景。
然而,在PMPU领域,基于CAT的评估平台尚未得到系统性开发。尽管已有研究者开发出通用型CAT平台,例如Oppl等人(2017)提出的AdaptiveTesting2系统,但其技术架构存在显著局限,尤其体现在对R统计计算平台的依赖上。具体而言,此类平台若采用进程调用方式集成R引擎,则存在对本地R运行环境的强依赖性,且主应用与R进程之间的异步执行机制导致任务调度与结果回传的同步控制复杂,影响系统响应效率与集成稳定性;若采用嵌入式接口模式,则要求R与JAVA虚拟机运行于同一物理节点并深度耦合,显著增加部署难度与后期维护成本,降低系统的可移植性与可扩展性;尽管远程服务模式(如Rserve)通过客户端/服务器架构实现了应用层与分析引擎的解耦,提升了系统健壮性,但其在特定操作系统(尤其是Windows平台)下对非英文字符集的支持能力有限,易引发编码错误,构成多语言应用场景下的关键技术瓶颈(向模军, 岐世峰, 2019)。
针对上述研究现状与技术挑战,本研究旨在实现两个目标:其一,开发一套面向PMPU评估的智能化CAT系统,解决PMPU领域大规模施测的问题。该系统采用JAVA语言独立实现核心测验算法(选题策略、能力估计算法等),避免对R统计平台的依赖,从而从根本上规避跨语言调用带来的部署复杂性、性能延迟与字符编码兼容性问题。其二,通过模拟研究验证该系统的准确性和效率。
2 研究方法
2.1 被试
研究1使用模拟数据,不采用真实被试。研究2使用真实被试的作答数据进行模拟研究。这些数据来自Guo等人(2024)推广CAT-PMPU成人版的研究。使用其中青少年的数据,共740份,删除存在缺失值的1名被试数据,最终得到有效数据739份。
2.2 研究流程
研究1旨在通过模拟研究比较R平台与PMPU-CAT平台的测验表现,以R平台的catR包为参照,检验PMPU-CAT平台在能力估计精度、预测误差和题目使用数量等方面的一致性,从而验证其在实际应用中的可靠性。具体而言,研究1使用R中的catR包生成模拟数据,并在R平台和PMPU-CAT平台上分别进行模拟测试。具体如下:生成1000个被试的θ值,根据θ值模拟生成他们在试题题库(89题)上的响应数据。研究采用最大Fisher信息(maximum Fisher information, MFI)作为项目选择策略,贝叶斯期望后验(expected a posteriori, EAP)作为能力估计方法,并设置三种停止规则(SE=0.30、SE=0.50、SE=0.70)。为了确保结果的可靠性,实验重复了100次,最终结果取平均值。
为了进一步验证PMPU-CAT平台估计的准确性,计算两种平台在不同停止规则下能力预测值与真实值之间的差异,采用绝对偏差(MAE)、均方误差(MSE)和均方根误差(RMSE)作为衡量指标。
研究2使用真实数据进行模拟研究,将问题性手机使用的纸笔(paper and pencil problematic mobile phone use, P&P PMPU)测验与PMPU-CAT测验在测验精度和测验效率两方面进行比较。其中纸笔测验的量表包含题库构建时用到的七个量表,分别是中文版无手机恐惧量表(NMP-C; 任世秀 等, 2020)、大学生手机成瘾倾向量表(MPATS; 熊婕 等, 2012)、大学生智能手机成瘾量表(SAS-C; 苏双 等, 2014)、成年人智能手机成瘾量表(SAS-CA; 陈欢 等, 2017)、移动手机成瘾量表(MPAS; Leung, 2008)、智能手机成瘾倾向量表(SAPS; Kim et al., 2014)、智能手机成瘾量表(SPAI; Lin et al., 2014)。具体如下:根据739名被试的响应数据,比较PMPU-CAT和P&P PMPU的测量误差和边际信度;再将P&P PMPU测验的测量误差设置为PMPU-CAT的停止规则,将两种测验方式的平均题目使用数量进行比较。
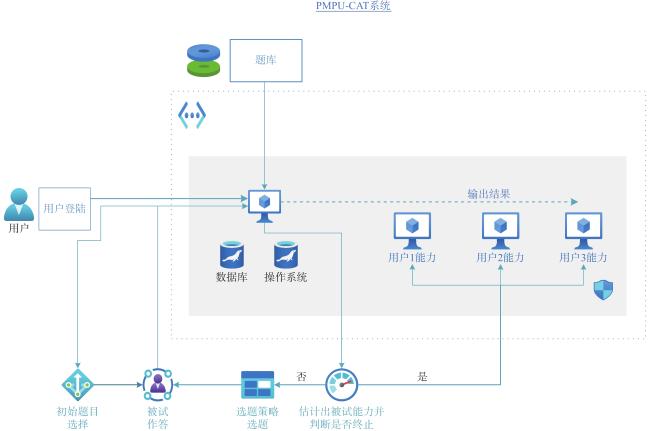
接下来将介绍PMPU-CAT平台采用的题库、IRT模型及CAT算法(CAT流程见图3 )。
2.3 试题题库
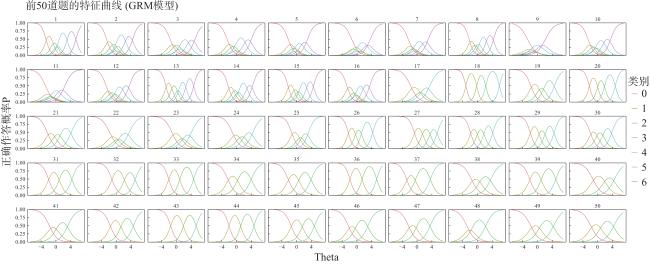
题库是CAT的基础,该平台使用的题库由Liu,Lu等人(2022)开发。题库在构建时进行了标准的分析,删除了质量不好的题目,最终保留了89道题目,这些题目具有良好的信效度(部分题目及参数见:https://osf.io/75tew/files/rf3kj)。具体而言,初始题库基于七个信效度良好的中文版PMPU量表整合而成,共包含98道题目。首先,采用主成分分析(principal component analysis, PCA)和单维性检验对题库进行初步筛选。根据PCA结果,因子载荷在第一主成分上低于0.40的条目被删除,共剔除5题,剩余93题。随后进行探索性因子分析(exploratory factor analysis, EFA),结果显示所有条目的因子载荷均大于0.40;第一特征值为35.63,第二特征值为6.11,二者比值为5.83(大于4),第一因子解释的方差为38.31%(大于20%),表明题库符合IRT的单维性假设。
在IRT模型选择方面,比较了拓广分部评分模型(generalized partial credit model, GPCM; Muraki, 1992)与等级反应模型(graded response model, GRM; Samejima, 1969)的拟合优度,主要依据AIC(Akaike, 1974)与BIC(Schwarz, 1978)。结果显示,GRM的AIC和BIC均低于GPCM,说明GRM对数据拟合更优。因此,在后续分析中采用GRM模型。基于被试作答数据,使用贝叶斯期望后验估计法拟合GRM模型,并输出各题目的区分度与难度参数。随后,对题目的区分度进行检验,剔除了区分度低于0.80的条目(李宇斌 等, 2020),最终保留89题。
此外,以性别为分组变量进行项目功能差异(differential item functioning, DIF)检验,结果表明所有题目的McFadden’s pseudo R2变化量均小于0.02,提示在性别层面不存在显著DIF,无需进一步剔题。最终,对保留的89题再次进行PCA、单维性检验、IRT模型选择、区分度和DIF分析,结果一致表明该题库整体满足单维性假设,题目区分度良好(均大于0.80),且不存在显著的性别差异。
2.4 IRT模型
在本研究中,题库中的项目均为单维多点计分,最终选择适合多分类数据的单维GRM作为测量模型(GRM具体介绍见:https://osf.io/75tew/files/2yevc)。
2.5 CAT算法
在平台开发过程中,初始题选择采取随机初始题选取方法;选题算法采取的是目前应用最为广泛的MFI方法,其中Fisher信息量反映的是可观察的样本数据X所携带的关于θ的信息数量(王孟成, 刘拓, 2023),其值越大,表明项目的可靠性越高。测验信息量是所有测验项目信息量之和。能力估计采用实际应用中最常使用的EAP估计方法。终止规则采用目前应用较广泛的标准误阈限值终止规则,即当被试能力估计的测量标准误低于某一预设值时终止测验,得到被试的能力估计值。相关数学表达式见公式1、公式2、公式3、公式4。
整个测验整体的可靠性通过边际信度(marginal reliability, MR)表示,MR通过所有受测者的平均测量标准误计算得到(Xu et al., 2020)。公式5、公式6如下。
其中N代表被试总人数,i代表第i个被试,$ SE({\theta }_{\mathrm{i}}) $ 代表第i个被试在最终θ估计值时的测量标准误。
3 PMPU-CAT平台介绍

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 结果
4.1 研究1结果
表1 R平台中三种停止规则下的模拟结果 |
| 终止规则 | 题目使用数量(R) | MSE(R) | MR(R) | r(R & True) | |
| M | SD | ||||
| SE(θ)=0.30 | 14.17 | 1.91 | 0.30 | 0.91 | 0.96 |
| SE(θ)=0.50 | 4.15 | 0.70 | 0.47 | 0.78 | 0.88 |
| SE(θ)=0.70 | 2.01 | 0.13 | 0.61 | 0.63 | 0.79 |
注:MSE(R)表示R平台中被试能力估计标准误的平均值,MR(R)表示R平台中不同的标准误差对应的不同边际信度,r(R & True)表示R平台估计出的能力值和能力真值的相关。 |
表2 PMPU-CAT平台中三种停止规则下的模拟结果 |
| 终止规则 | 题目使用数量 (JAVA) | MSE(JAVA) | MR (JAVA) | r (JAVA & True) | r (R & JAVA) | |
| M | SD | |||||
| SE(θ)=0.30 | 15.04 | 1.97 | 0.30 | 0.91 | 0.96 | 0.98 |
| SE(θ)=0.50 | 4.59 | 0.67 | 0.48 | 0.77 | 0.88 | 0.94 |
| SE(θ)=0.70 | 2.16 | 0.37 | 0.65 | 0.58 | 0.76 | 0.82 |
注:MSE(JAVA)表示JAVA平台中被试能力估计标准误的平均值,MR(JAVA)表示PMPU-CAT平台中不同的标准误差对应的不同边际信度,r(JAVA & True)表示PMPU-CAT平台估计出的能力值和能力真值的相关,r(R & JAVA)表示R平台估计出的能力值和PMPU-CAT平台估计出的能力值的相关。 |
表3 两种平台在不同停止规则下的预测误差 |
| 终止规则 | MAE (R) | MAE (JAVA) | MSE (R) | MSE (JAVA) | RMSE (R) | RMSE (JAVA) |
| SE(θ)=0.30 | 0.24 | 0.24 | 0.09 | 0.09 | 0.30 | 0.30 |
| SE(θ)=0.50 | 0.38 | 0.38 | 0.23 | 0.23 | 0.48 | 0.48 |
| SE(θ)=0.70 | 0.49 | 0.52 | 0.38 | 0.43 | 0.61 | 0.65 |
4.2 研究2结果
表4 相同测验长度下两种测验方法的测量误差 |
| 测验方法 | 测验长度 | 测量误差 | |||
| M(SD) | SE降低百分比(%) | t | Cohen’s d | ||
| NMP-C | 16 | 0.34(0.06) | 11.8 | 19.19*** | 0.71 |
| PMPU-CAT | 16 | 0.30(0.04) | |||
| MPATS | 14 | 0.40(0.04) | 20.0 | 48.23*** | 1.77 |
| PMPU-CAT | 14 | 0.32(0.04) | |||
| SAPS | 7 | 0.55(0.02) | 23.6 | 75.20*** | 2.77 |
| PMPU-CAT | 7 | 0.42(0.05) | |||
| SPAI | 18 | 0.41(0.02) | 29.3 | 82.39*** | 3.03 |
| PMPU-CAT | 18 | 0.29(0.04) | |||
| SAS-C | 11 | 0.43(0.04) | 18.6 | 41.11*** | 1.51 |
| PMPU-CAT | 11 | 0.35(0.04) | |||
| SAS-CA | 14 | 0.36(0.04) | 11.1 | 25.47*** | 0.94 |
| PMPU-CAT | 14 | 0.32(0.04) | |||
| MPAS | 9 | 0.48(0.05) | 20.8 | 46.62*** | 1.72 |
| PMPU-CAT | 9 | 0.38(0.05) | |||
注:***p<0.001,以下同。 |
表5 相同测验长度下两种测验方法的测量信度 |
| 测验方法 | 测验长度 | 测量信度 | |||
| M(SD) | MR增加百分比(%) | t | Cohen’s d | ||
| NMP-C | 16 | 0.88(0.04) | 3.4 | 17.48*** | 0.64 |
| PMPU-CAT | 16 | 0.91(0.03) | |||
| MPATS | 14 | 0.84(0.03) | 7.1 | 44.51*** | 1.64 |
| PMPU-CAT | 14 | 0.90(0.03) | |||
| SAPS | 7 | 0.69(0.02) | 18.8 | 74.00*** | 2.72 |
| PMPU-CAT | 7 | 0.82(0.05) | |||
| SPAI | 18 | 0.83(0.02) | 9.6 | 84.96*** | 3.13 |
| PMPU-CAT | 18 | 0.91(0.03) | |||
| SAS-C | 11 | 0.82(0.03) | 6.1 | 37.49*** | 1.38 |
| PMPU-CAT | 11 | 0.87(0.04) | |||
| SAS-CA | 14 | 0.87(0.03) | 3.4 | 22.29*** | 0.82 |
| PMPU-CAT | 14 | 0.90(0.03) | |||
| MPAS | 9 | 0.76(0.04) | 11.8 | 42.87*** | 1.58 |
| PMPU-CAT | 9 | 0.85(0.04) | |||
表6 基于P&P PMPU测试的七个停止规则下的模拟结果 |
| 精度 | P&P PMPU长度 | PMPU-CAT长度 |
| SE(NMP-C)=0.34 | 16.00 | 13.00 |
| SE(MPATS)=0.40 | 14.00 | 8.44 |
| SE(SAPS)=0.55 | 7.00 | 4.19 |
| SE(SPAI)=0.41 | 18.00 | 8.02 |
| SE(SAS-C)=0.43 | 11.00 | 7.15 |
| SE(SAS-CA)=0.36 | 14.00 | 11.05 |
| SE(MPAS)=0.48 | 9.00 | 5.62 |
传统的P&P PMPU和相同测验长度的PMPU-CAT的测量误差结果如表4 所示。可以看出,与P&P PMPU测验相比,PMPU-CAT显著降低了11.1%~29.3%(M=19.3%)的测量误差(p<0.001,Cohen’s d>0.71)。当测试长度较短时,传统的P&P PMPU测验的测量误差较大。PMPU-CAT可以显著提高测量精度。例如,在7项的SAPS中,传统的P&P PMPU测验的测量误差为0.55,这是不可接受的(Xu et al., 2020),而PMPU-CAT的测量误差仅为0.42。
传统的P&P PMPU和相同测验长度的PMPU-CAT的测验信度结果如表5 所示。可以看出,与P&P PMPU相比,PMPU-CAT显著提高了3.4%~18.8%(M=8.6%)的测验信度(p<0.001, Cohen’s d>0.64)。当测试长度较短时,传统的P&P PMPU测验的测验信度较低。PMPU-CAT可以显著提高测量精度。结果表明,在相同测验长度下,PMPU-CAT可以显著减小测量误差,提高测量精度。
为了比较P&P PMPU和PMPU-CAT测验之间的效率,七个P&P PMPU测验的测量误差被设置为PMPU-CAT的停止规则,计算七个停止规则下PMPU-CAT的平均项目使用量。具体结果如表6 所示,以P&P SPAI为例,当被试完成18个项目时,P&P PMPU测验的SE=0.41。相比之下,在PMPU-CAT测验中,被试只需要完成8.02个项目就可以达到与P&P SPAI相同的准确性。
5 讨论
本研究开发了问题性手机使用计算机化自适应测验平台—PMPU-CAT,旨在提升PMPU评估的效率与精度。通过模拟与真实数据验证,平台在测量准确性、测验效率与技术实现方面均表现出良好性能。
首先,为验证平台算法实现的正确性,本研究将其与广泛使用的R平台进行对比。结果显示,在三种终止规则下,PMPU-CAT与R平台的MAE、MSE和RMSE值高度接近,表明本平台在能力估计上具有与成熟工具相当的准确性,算法实现可靠。
其次,在测验效率方面,PMPU-CAT显著优于P&P PMPU测验。基于真实数据的模拟表明,PMPU-CAT在保证测量精度的同时,大幅缩短测验长度。例如,在标准误差SE=0.43条件下,PMPU-CAT平均仅需7.15题,而SAS-C需固定施测11题。此外,被试仅完成5个项目时,其能力估计与完整测验的相关系数已达0.88,这一效率与其他领域CAT研究高度一致(如大学生饮食失调测验; Liu, Zhang, et al., 2022),印证了CAT技术在降低作答负担方面的核心优势(Petersen et al., 2024)。
在测量精度方面,PMPU-CAT同样达到领域基准水平。当以SE=0.30为终止标准时,PMPU-CAT平台的MAE为0.24,RMSE为0.30,与情绪智力CAT的跨领域研究表现相当(MAE=0.25, RMSE=0.32; 张龙飞 等, 2020)。在固定长度为11题的条件下,PMPU-CAT的测量误差为0.35,与网络成瘾CAT的0.29相近(Zhang et al., 2019)。这表明PMPU-CAT在提升效率的同时,未牺牲测量精度。
技术实现上,PMPU-CAT采用纯JAVA语言开发,区别于Concerto等依赖JAVA与R混合架构的平台(Scalise & Allen, 2015)。该设计避免了外部统计环境依赖与系统兼容性问题,部署更简便,更适合教育与心理健康领域的实际应用场景。
为更系统地展现PMPU-CAT平台相较于现有评估工具的技术优势与应用特点,表7 从技术实现、测量性能、测验效率及适用场景等多个维度,系统比较了PMPU-CAT平台、R平台(catR包)以及传统P&P测验(如SAS-C)的核心特征。该对比不仅整合了前述模拟研究的结果,也突出了本平台在实际应用中的综合优势。可以看出,PMPU-CAT平台采用纯JAVA语言开发,摆脱了对R等外部统计环境的依赖,显著降低了系统部署的复杂性和兼容性风险,更适合在教育、心理卫生等实际场景中进行大规模部署。在测量性能方面,平台具备灵活的终止机制以适应不同精度需求。相比传统P&P测验题量固定、效率低下等问题,PMPU-CAT通过自适应选题算法动态匹配被试能力,大幅减少作答负担(如仅需7.15题即可达到SAS-C 11题的精度)。此外,平台基于专门构建的PMPU单维题库(89题,GRM模型),确保了测量内容的全面性与科学性。综上,PMPU-CAT平台在保持高测量精度的同时,兼具高效性、易用性与可扩展性,为问题性手机使用的智能化评估提供了切实可行的技术路径。
表7 PMPU-CAT平台与其他评估平台的多维度性能对比 |
| 维度 | PMPU-CAT平台 | R平台(catR包) | 传统P&P测验(如SAS-C) |
| 技术实现语言 | 纯JAVA开发 | R语言为主 | 无 |
| 部署复杂度 | 单一语言,部署简单,兼容性强 | 需R环境支持 | 无需技术部署 |
| 计算依赖 | 不依赖外部统计软件 | 依赖R环境 | 无 |
| 测量精度(SE/MR) | 高(SE=0.43时,MR=0.82);可通过设置SE控制测验精度 | 与PMPU-CAT接近 | 较高(SE>0.35) |
| 测验效率(平均题量) | 高(SE=0.43时,仅需7题) | 与PMPU-CAT接近 | 固定(SAS-C 11题,SE=0.43) |
| 自适应算法 | MFI选题+EAP估计+SE终止 | 支持同类算法 | 无自适应机制 |
| 题库支持 | PMPU题库(89题,GRM模型) | 支持 | 一般为单一量表 |
| 应用场景 | 适合大规模、高效率筛查 | 适合模拟研究 | 小规模施测 |
尽管本研究取得了一定的成果,但仍存在局限:本研究采用MFI的项目选择策略,该策略被广泛应用于CAT研究中,但在测验初期可能导致题目选择不当(Chang & Ying, 2008)。针对此问题,未来研究可以引入基于KL散度的全局信息量选题算法(Chang & Ying, 1996),可在测验初期提供更稳定的项目选择。
除此之外,本研究中PMPU-CAT平台的题库包含多种计分方式的题目。这种不一致性可能影响题目参数的估计精度和测验结果的可比性。未来研究可以将题库中的题目统一为一致的计分方式,并重新估计题目参数,以进一步提升测验的准确性。
6 结论
本研究使用JAVA语言开发了一个基于IRT的PMPU-CAT平台,平台具有良好的测验精度和测验效率。与已有的R环境相比,两种平台的表现具有强相关,这证明了本平台的可靠性。与传统P&P PMPU测验相比,PMPU-CAT平台具有更好的测验精度和测验效率。这表明本平台适用于教育和心理评估等多个领域,可以为相关研究和实践提供强有力的技术支持。